Harness Engineering:把会写代码的模型,变成真正能交付的软件系统
引子:AI 编程的分水岭,不是会不会写代码,而是能不能持续交付
过去一年,AI 编程最迷人的一幕,通常发生在演示视频的前两分钟。
你说一句“做一个 Notion 风格的笔记应用”,模型立刻起手一个漂亮首页;你再补一句“加上登录、搜索和评论区”,它继续往前冲,像一位不知疲倦、态度极好的初级工程师。于是很多人自然得出一个判断:既然模型已经会写代码,软件工程的核心问题似乎只剩下“把需求说清楚”。
这个判断只对了一半。
模型确实越来越会写代码,但真正的软件工程从来不是“写出第一版代码”。真正困难的部分是:需求会变,代码会腐烂,系统会积累历史包袱,团队会分工,权限会分层,线上会出事故,昨天的正确会变成今天的 bug,今天的最优解会变成三个月后的技术债。
一句话做出一个 demo,不等于一句话维护一个系统。
OpenAI 在关于 Codex 的几篇工程文章里反复强调一件事:当智能体开始承担真实的软件交付工作后,人类工程师的主业就不再只是敲代码,而是设计环境、明确意图、建立反馈回路,并把应用、日志、指标、协议和文档变成智能体可以理解、操作和验证的系统。Anthropic 对长时运行智能体的研究也指向同一个结论:如果没有初始化脚手架、进度制品、会话交接、评估器和更严格的上下文工程,模型很容易在长任务中迷路、烂尾,或者更危险地,在一种看似自信的状态下,把错误带进生产环境。
这就是 Harness Engineering 的起点。
它不是一个时髦名词,也不是“给模型套个壳”。它更像一整套工程约束系统:把概率性的模型输出,转译成长期、可靠、可验证、可审计、可回滚的软件交付流程。
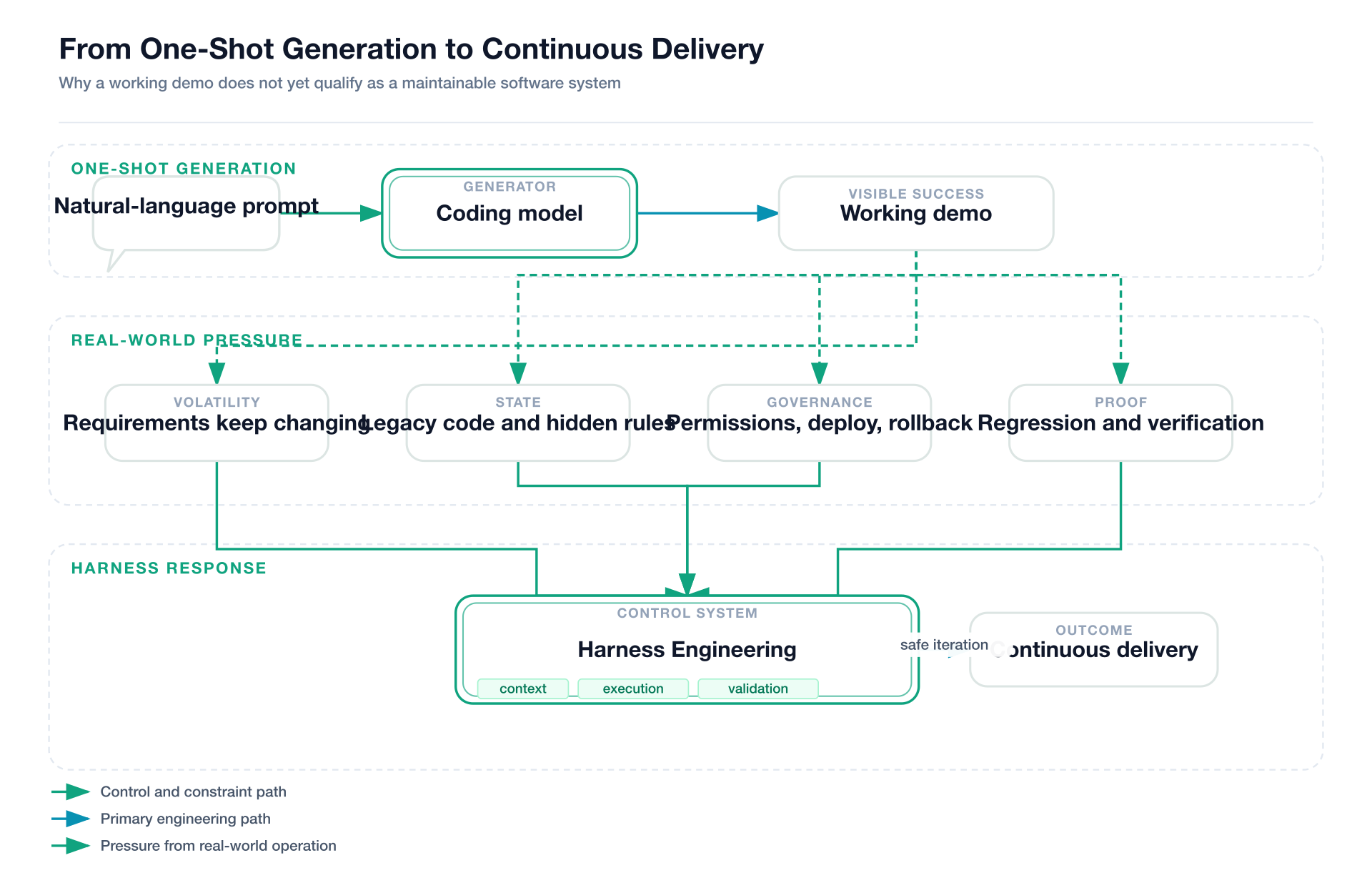
图 1:真正的工程难点,不在“生成第一版”,而在把第一版安全地接入长期运行的系统。
一、真正的断层:模型按会话工作,工程按系统运行
理解 Harness,最好不要从 Prompt 开始,而要先承认一个现实:大模型面对的不是“写代码”这个单点任务,而是在一个有状态世界里连续做对很多件事。
这中间至少有四道断层。
1. 时间断层:模型按窗口工作,项目按周和月生长
模型天然以会话为单位工作。哪怕上下文窗口再大,它也不等于“持续记忆”。Anthropic 在长时运行智能体的实验里观察到,模型跨越多个上下文窗口后,会出现一些典型失效模式:
- 想一次做完太多,结果在半路耗尽上下文。
- 留下一半实现、一半猜测的现场,让下一轮继续接锅。
- 看到项目里已经“有些东西能跑”,就误判为任务完成。
这很像轮班交接。一个工程师下午六点下班,另一个工程师晚上九点接手,如果没有清晰的任务列表、状态记录、运行脚本和提交历史,第二个人不是在开发,而是在考古。
所以 Harness 的第一层价值,不是“让模型更聪明”,而是让它每次醒来都知道自己在哪、上一轮做了什么、这轮该推进什么、结束时要把现场收成什么样子。
2. 状态断层:模型是概率机器,生产系统是确定性机器
模型靠分布生成下一个 token,生产系统靠约束维护状态一致性。这两者并不天然兼容。
银行转账不是“差不多成功”;权限模型不是“八成没问题”;订单履约不是“页面上看起来像已经提交”。模型可以在语言上非常流畅,但只要它对真实系统状态的理解稍微偏离,输出就会从“效率工具”滑向“事故源”。
因此,Harness 必须建立边界:
- 哪些文件能改,哪些不能改。
- 哪些工具能用,哪些需要审批。
- 哪些状态能写,哪些只能读。
- 哪些结果可以直接合并,哪些必须经过验证。
换句话说,Harness 不是模型的装饰物,而是它进入真实系统时的物理边界。
3. 验证断层:生成越来越便宜,证明正确仍然很贵
今天的大模型生成代码越来越便宜,但验证并没有同步变便宜。
真正昂贵的不是“写一个新功能”,而是回答下面这些问题:
- 这个功能有没有破坏旧逻辑?
- 页面是不是只是“长得像可用”,其实关键流程点不动?
- 日志和指标是否暴露了性能退化?
- 智能体是否在用一种危险但暂时没炸的方式工作?
OpenAI 在 Codex 的内部工程实践里,把应用 UI、Chrome DevTools、日志、指标和 trace 变成对智能体可读的对象;Anthropic 在应用开发 harness 中,则用生成器加评估器的方式逼迫模型接受外部批改,而不是自我陶醉式地宣布胜利。
这说明一个残酷但重要的事实:
在 AI 软件工程里,真正值钱的不是“让模型干活”,而是“让模型有资格说自己干完了”。
4. 熵增断层:代码库会学坏,智能体会复制坏习惯
只要代码库里已经存在坏模式,智能体就会继续复制它。只要文档过时、目录混乱、命名漂移、脚手架不一致,模型就会在更高吞吐下把这些问题成倍放大。
OpenAI 在 agent-first 的工程实验中提到,他们最后不得不把“黄金规则”编码进代码库和 lint,把文档维护、质量评分、结构校验和后台重构做成持续运行的清理循环。原因很简单:没有垃圾回收的智能体代码库,不会自然收敛,只会越长越乱。
Harness 在这里扮演的,就是工程领域的垃圾回收器。
二、Harness 到底是什么:不是外壳,而是控制系统
如果只用一句话来定义,我会这样说:
Harness Engineering 不是让模型多会一点,而是让模型在一个长期运行的工程系统里,知道怎么开始、如何推进、用什么边界、按什么标准结束,并在失败时可以被拉回来。
它至少包含六层。
1. 上下文层:给模型地图,而不是给它一座档案馆
OpenAI 的一个关键经验是:不要把 AGENTS.md 写成百科全书,而要把它写成目录。真正的知识应分散在结构化文档、产品规格、架构说明、执行计划、技术债记录、设计参考和自动生成的 schema 中。
这件事的本质是:
- 模型不怕信息少,怕的是信息乱。
- 模型不怕文档短,怕的是不知道去哪找真相。
- 模型不怕逐步读取,怕的是一上来就被灌一千页陈旧说明书。
好的 Harness 会把“上下文工程”做成可导航系统,而不是一次性大灌输。
2. 执行层:让模型有手,但不要让它乱伸手
真正能工作的智能体,不只是会回答问题,还要能做事:读文件、跑命令、看页面、启动服务、调用工具、发起 PR、读取日志、生成补丁。
但“能做事”不等于“什么都能做”。所以执行层要同时解决两件事:
- 给模型足够强的执行能力。
- 给这份能力加上沙箱、协议和审批。
Anthropic 的工具设计文章里反复强调,工具要命名清晰、描述明确、返回足够上下文但不浪费 token;OpenAI 的 App Server 则更进一步,把线程、轮次、项目、审批、流式消息和工具执行都规范成协议原语。这意味着“智能体做事”不再是一团魔法,而是一条可以被 UI、IDE、CLI、桌面应用共同复用的可观察链路。
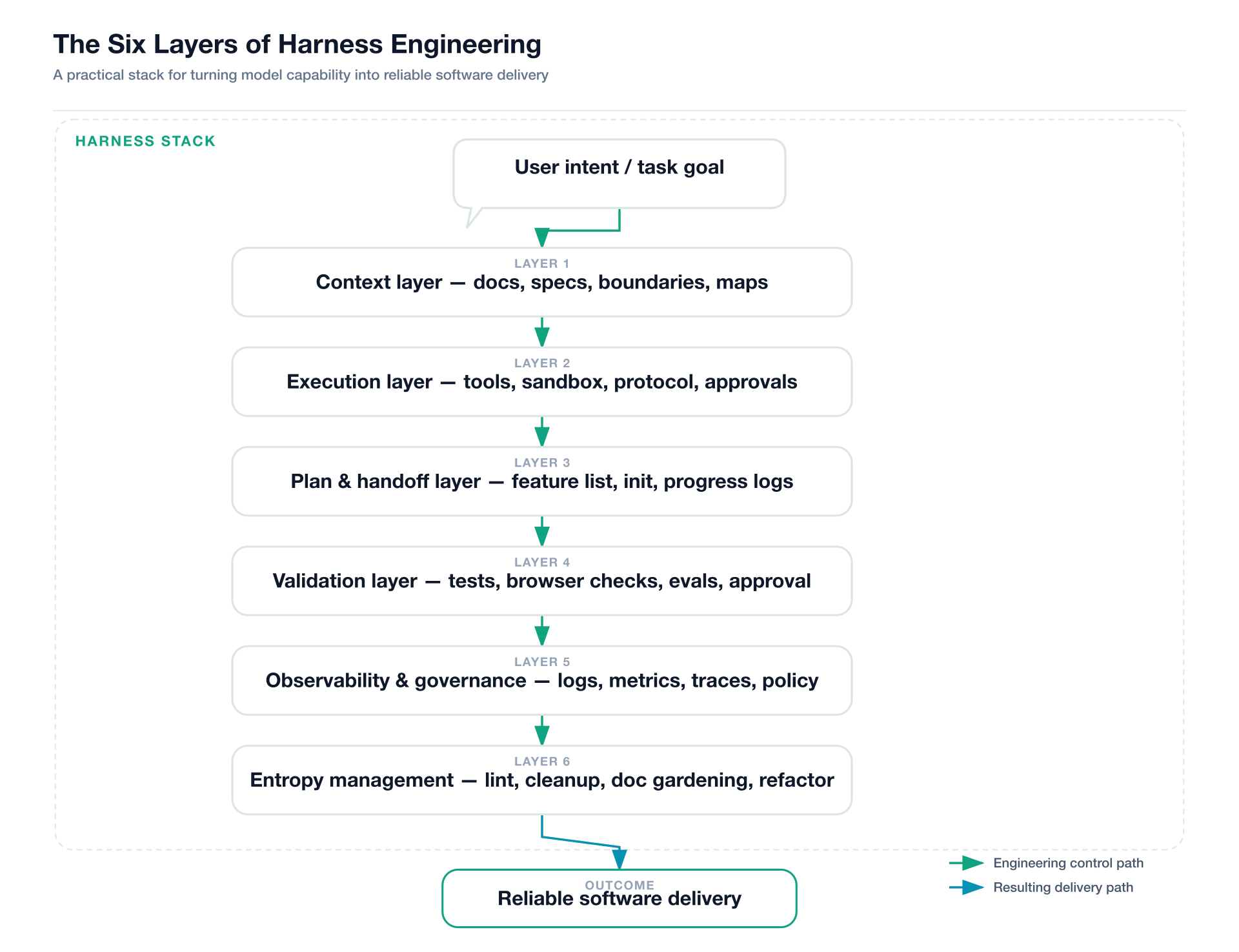
图 2:Harness 不是单个脚本,而是一条从意图到交付的分层工程链路。
3. 计划与交接层:让每一轮都像一位守纪律的接班工程师
Anthropic 给出的一个很有启发性的实践是:
- 第一轮不是直接开发,而是初始化。
- 初始化智能体先建立
init.sh、进度文件、功能列表、初始提交。 - 之后每一轮编码智能体只做增量推进,并留下结构化状态。
这其实是在把“工程项目的组织纪律”显式写给模型:
- 先盘点。
- 再选择单个目标。
- 做完留痕。
- 交接要干净。
没有这一层,长任务就会退化成一连串临场发挥。短期看很热闹,长期看很难收敛。
4. 验证层:把“我觉得差不多了”变成“证据显示可以合并”
这是 Harness 最容易被低估,也最决定成败的一层。
验证不只是跑单元测试。真正有效的验证层至少包括:
- 单元测试与集成测试
- 端到端浏览器验证
- 结构化评估 rubric
- 回归检查
- 性能或稳定性基线
- 人类审批点
Anthropic 在前端设计与全栈应用 harness 里,明确把生成器和评估器拆开,就是因为模型对自己的产出往往过于宽容。OpenAI 则通过让 Codex 直接读取 DOM、日志、metrics 和 traces,把“验证工作”本身也纳入智能体的可操作范围。
换言之,Harness 的目标不是让错误永不发生,而是让错误更早暴露,并更便宜地被纠正。
5. 观测与治理层:让智能体在越界之前就被看见
如果系统要跑上数小时、数天,甚至多智能体并行,那么“可观察性”就不再是运维团队的额外选修课,而是智能体工程的主干。
你至少要知道:
- 它正在做什么。
- 为什么卡住。
- 哪个工具调用失败。
- 哪一步最耗时。
- 哪段流程反复返工。
- 哪次审批最常被拒。
同时,治理也必须同步存在:
- 命令是否需要审批。
- 哪些命令可自动放行。
- 哪些仓库允许自动合并。
- 单次运行预算是多少。
- 什么情况下必须交给人工。
没有治理的智能体不是自主,而是失控。
6. 熵管理层:定期清理,胜过一次大修
这是很多团队最晚意识到、却最难补上的一层。
当智能体产能提升之后,代码库会以惊人的速度积累“看起来没坏、其实很脏”的东西:
- 重复 helper
- 风格漂移
- 命名失真
- 过期文档
- 目录膨胀
- 奇怪的粘合层
OpenAI 把这件事叫作垃圾回收。这个比喻很准确,因为技术债在智能体时代不再只是线性增长,而会被高吞吐放大。你不定期清理,它就会变成后续所有生成的训练现场。
三、什么时候需要 Harness,什么时候不要过度设计
并不是所有任务都值得上复杂 Harness。
这是一个常见误区:看到“多智能体”“长时运行”“规划器/评估器”,就觉得越复杂越先进。恰恰相反,Anthropic 和 OpenAI 的经验都指向同一个原则:先用最简单的系统解决问题,只有在失败模式稳定出现时,才增加结构。
可以把任务分成三类。
第一类:一次性生成任务
例如:
- 生成一个落地页
- 写一个小脚本
- 做一个静态 demo
- 生成邮件模板或 SQL 查询
这类任务主要追求速度,不一定需要复杂 Harness。单智能体加基本工具,再做一次验证,往往就够了。
第二类:短周期可回滚任务
例如:
- 给现有项目加一个明确功能
- 修一个定位清晰的 bug
- 做一轮限定范围的重构
这时候你需要最小 Harness:
- 读 repo
- 写 patch
- 跑测试
- 看 diff
- 留提交记录
如果团队还没有形成文档地图、目录边界和基础验证,问题会开始出现,但通常还没到灾难级别。
第三类:长时运行的产品级任务
例如:
- 连续数天迭代一个新产品
- 在老系统上持续引入智能体协作开发
- 让模型自主推进前端、后端和评估
- 多智能体并行处理不同模块
这时如果还沿用“给个 prompt 直接跑”的方式,系统几乎必然会在某个地方塌掉。因为你需要解决的已经不是生成,而是:
- 跨会话记忆
- 任务切片
- 状态交接
- 验证闭环
- 权限治理
- 质量清理
Harness 真正适用的,不是任何有 AI 的地方,而是任何开始出现“持续性、状态性、协作性和风险性”的地方。
四、从失败模式出发,反推一套真正有用的 Harness
与其从抽象概念出发,不如直接从常见失败模式出发。
| 失败模式 | 典型表现 | 对应 Harness 对策 |
|---|---|---|
| 智能体一次做太多 | 半路耗尽上下文,留下烂尾现场 | 任务拆分、功能列表、单轮单目标 |
| 智能体过早宣布完成 | 页面看起来像成了,深层功能没通 | 评估器、端到端测试、功能验收清单 |
| 会话切换后失忆 | 下一轮只能靠猜,重复劳动严重 | 进度文件、交接制品、提交历史、初始化脚本 |
| 看不见真实运行状态 | 只会读代码,不会读现象 | 浏览器自动化、日志、指标、trace 接入 |
| 工具调用混乱 | 跑了危险命令或拿不到关键上下文 | 明确工具描述、权限边界、审批策略 |
| 代码库越跑越脏 | 重复代码、文档失真、风格漂移 | lint、结构测试、文档巡检、周期性清理任务 |
这个表很重要,因为它说明了一件事:
Harness 不是靠信仰堆出来的,而是靠失败模式倒逼出来的。
每多一层结构,都应该对应一个真实、稳定、可复现的失效来源。否则它就只是新形式的样板工程。
五、最小可用 Harness:先搭闭环,再谈平台
如果读完前面你只觉得“有道理”,但不知道怎么开始,那文章还是失败的。下面这套方案,不追求宏大,而追求今天能做、下周能跑、一个月后能收敛。
第一步:先搭“地图”,不要先搭“智能”
先别急着上多智能体。先把下面这些文件和目录补齐:
AGENTS.md
docs/
├── product/
│ ├── overview.md
│ └── feature-list.md
├── architecture/
│ ├── overview.md
│ ├── boundaries.md
│ └── invariants.md
├── plans/
│ ├── active/
│ └── completed/
└── runbooks/
├── local-dev.md
└── release-checklist.md
scripts/
├── init.sh
├── dev-smoke.sh
└── verify.sh
evals/
└── acceptance/
这套结构有三个原则:
AGENTS.md只写最核心的执行规则和导航入口。- 真正容易变化的知识,放进
docs/,让它可更新、可索引、可版本化。 - 所有“怎么启动、怎么验证、怎么交接”的动作,都变成脚本,而不是口口相传。
第二步:给智能体一个干净的起手式
每次进入任务时,不要让它直接编码。先要求它固定执行一段开场动作:
- 读取当前任务说明。
- 读取
AGENTS.md。 - 读取相关架构文档和 feature list。
- 查看最近提交和未完成计划。
- 运行
scripts/init.sh。 - 跑一次最小 smoke test。
- 再开始改动。
这听起来有点啰嗦,但这是让模型进入“工程态”而不是“作文态”的关键。
第三步:要求它只做增量,不准豪赌
给模型的默认规则应该是:
- 一轮只推进一个明确目标。
- 每轮结束必须写清楚做了什么、还有什么没做。
- 如果修改超出预期范围,必须先说明原因。
- 没验证过,不能标记完成。
Anthropic 在长时运行 harness 里专门让智能体维护 feature list 和 progress file,这个做法非常值。因为它解决的不是记录问题,而是抑制模型的自我脑补。
第四步:把“能不能合并”从主观判断改成证据集合
一个最小可用的完成标准,可以长这样:
- 单元测试通过。
- 关键路径 smoke test 通过。
- 若涉及 UI,浏览器自动化验证通过。
- 若涉及性能,至少有一条指标对比。
- 若涉及新增能力,feature list 中有对应项被验证。
- 变更说明能回答“改了什么、为什么这样改、还有什么风险”。
你会发现,这里面几乎没有一句“感觉差不多”。这正是目的。
第五步:让它看见运行时,不要只让它看见源码
很多团队给了模型整个仓库,却没给它任何运行态信息。这等于让一个工程师闭眼修车。
至少补上这些入口:
- 浏览器自动化
- 开发日志
- 错误堆栈
- 基础指标
- 关键流程录屏或截图能力
OpenAI 把应用 UI、日志、metrics 和 trace 都做成 Codex 可读对象,这个方向非常对。因为一旦模型能看到现象,它就不再只是在文本层面“猜系统”,而是在系统层面“读系统”。
第六步:一开始不要上太多 agent,先上“一个生成器 + 一个挑刺的人”
如果你要加第二个角色,不要先加更多执行者,先加评估者。
原因很简单:多数团队的第一性问题不是“生成太慢”,而是“生成太轻率”。
一个实用的最小组合是:
- 生成器:负责实现。
- 评估器:负责找漏、找假完成、找体验缺口。
等这个闭环跑顺之后,再考虑规划器、专职测试 agent、文档 agent、清理 agent。
第七步:固定做“熵管理”,不要把清理留给未来的你
每周至少做一次:
- 扫描重复 helper。
- 清理失效文档。
- 更新 feature list 和 plans。
- 回收一次性脚手架。
- 运行结构 lint。
- 做一轮小规模 refactor。
不要等“项目稳定了再整理”。在智能体时代,项目从来不会自然稳定,它只会在高吞吐下更快偏离。
六、如果只有两周,先把这条小闭环跑起来
很多人读到这里,最大的问题不是“我同不同意”,而是“这套东西看起来对,但团队没有那么多时间和资源,一上来根本搭不出完整版”。
这是正常的。Harness 不需要从第一天就像一家大公司的内建平台那样完整。真正有效的做法,是先搭出一条能跑的小闭环,再让系统自己长骨头。
如果你只有两周,我建议按下面这个节奏来。
第 1 - 2 天:把知识入口收紧
目标不是写更多文档,而是让智能体知道先读什么。
- 把
AGENTS.md压缩成 100 行以内的执行规则与导航入口。 - 建一个最小
docs/结构,只保留产品概览、架构边界、运行方式。 - 把“不要做什么”写清楚,例如禁止改哪些目录、禁止绕过哪些验证。
这两天的成果不在于内容多,而在于仓库第一次出现“结构化入口”。
第 3 - 4 天:把启动和验证脚本化
这一步的目标,是让智能体不再靠猜来操作环境。
- 写
scripts/init.sh,保证本地服务、依赖、环境变量能一键起。 - 写
scripts/dev-smoke.sh,覆盖最关键的三到五条主路径。 - 写
scripts/verify.sh,把测试、lint、最小验收揉成一条固定命令。
如果一支团队连“怎么启动”和“怎么验收”都还依赖口头传承,就还没到谈高阶 agent orchestration 的阶段。
第 5 - 7 天:把“完成”显式化
从这一步开始,智能体才真正有机会进入长任务。
- 建 feature list,把需求拆成若干可验证项。
- 建 progress log,让每轮运行结束时留下状态摘要。
- 规定一轮只处理一个明确目标,禁止“顺手大改一片”。
做到这里,你已经拥有最小的交接系统了。它可能还不优雅,但已经能显著降低模型在多轮会话中的漂移。
第 8 - 10 天:加上一个挑刺者
先不要急着加更多执行 agent,先加评估者。
- 如果是 UI 任务,就让评估者接浏览器自动化。
- 如果是服务端任务,就让评估者重点看回归、日志和边界情况。
- 如果是重构任务,就让评估者专门检查范围外变更和架构越界。
这一步的关键,不是把评估做得“绝对正确”,而是阻止生成器在自我表扬中提前收工。
第 11 - 14 天:把高风险动作纳入治理
到第二周的后半段,开始收权限。
- 哪些命令自动放行,哪些必须审批。
- 哪些目录允许写,哪些目录默认只读。
- 哪些变更允许自动合并,哪些必须人工过眼。
- 单次运行预算和超时阈值设多少。
走到这一步时,你已经有了一套不是特别华丽、但足够可靠的最小 Harness。它可能还不“聪明”,却已经开始像工程系统,而不是一个热闹的提示词秀场。
七、工程师接下来真正该练的,不再只是编码速度
如果 Harness 成立,那么工程师的价值也会随之重排。
我不认为“程序员会消失”这种说法严肃,但我非常认同一件事:只会把模糊需求翻译成代码的人,会越来越不值钱;能把复杂现实翻译成系统边界、评估标准和交付节奏的人,会越来越值钱。
未来更稀缺的,不是“写得快”,而是下面四种能力。
1. 定义完成
你能不能把“做出来”写成一组可验证条件,而不是一句模糊评价?
2. 设计边界
你能不能把一个系统拆成哪些地方允许智能体自由发挥、哪些地方必须被严管?
3. 理解业务里的脏现实
很多真正重要的规则,根本不在代码里,而在流程、习惯、灰度策略、审批链、风控逻辑和组织默契里。谁能把这些东西结构化,谁就掌握了智能体时代的高分辨率上下文。
4. 持续校准系统
Harness 不是一次性交付物,而是活的基础设施。它要随着模型能力、团队习惯、任务类型和事故经验持续更新。你不是在写一个完美框架,而是在维护一套会自我进化的编排系统。
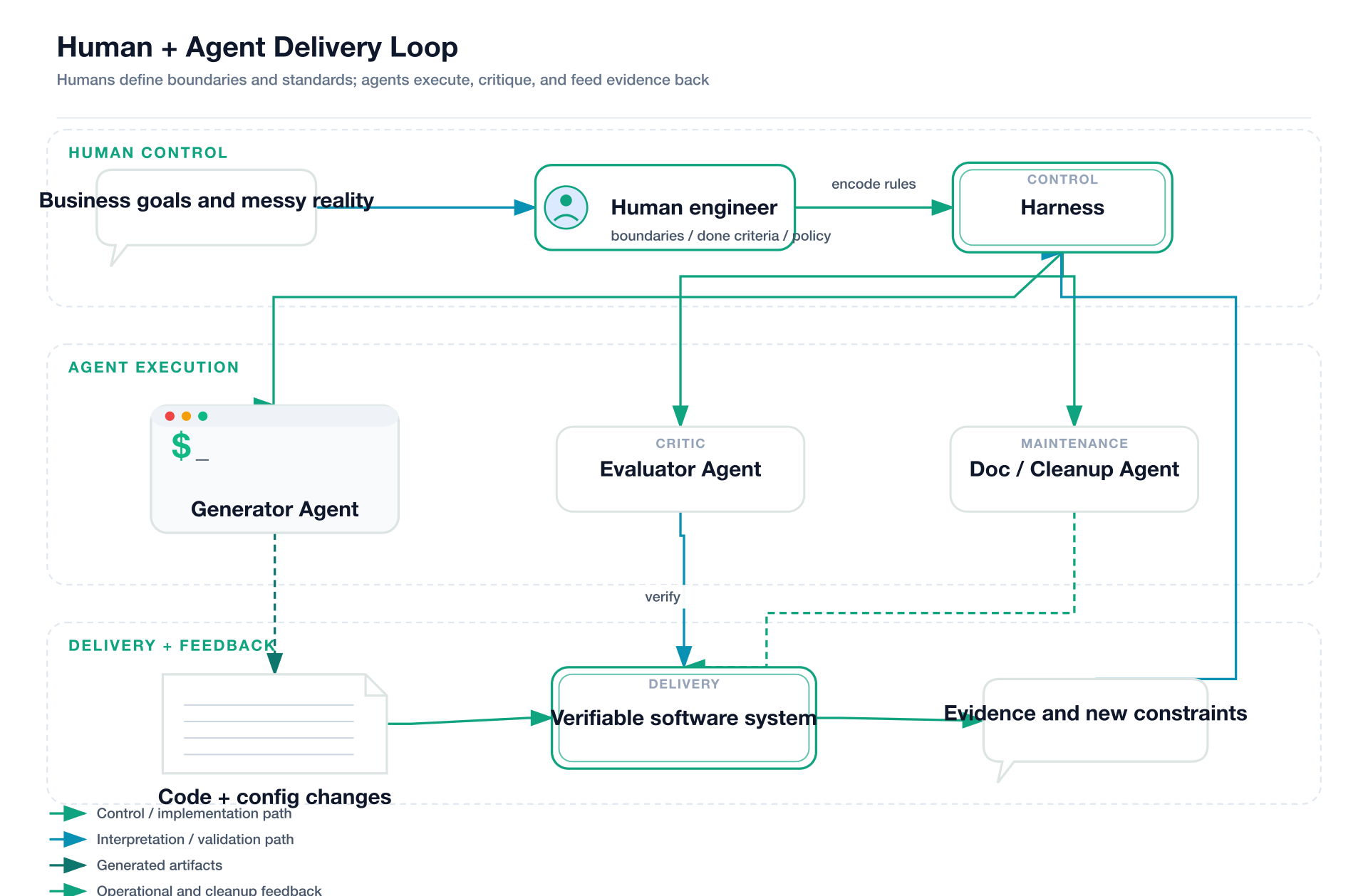
图 3:未来更像“人类负责约束与校准,智能体负责执行与反馈”的闭环,而不是简单的人力替代。
八、最后的判断:Harness 不会消失,它会下沉成新的工程底座
很多人把 Harness 想成一个过渡概念,仿佛模型再强一点,它就会被吞掉。
我恰恰持相反看法。
模型越强,Harness 不是越不重要,而是越基础、越隐形、越像操作系统。
因为模型变强之后,问题不会停留在“能不能生成”,而会迅速升级为:
- 能不能连续几小时推进复杂任务。
- 能不能在多次交接里保持状态一致。
- 能不能在改动中不破坏旧世界。
- 能不能自己验证,而不是自我表扬。
- 能不能在被授权时真正可靠,在不该越界时真正收手。
当这些问题出现时,答案都不会来自“再写一个更好的 prompt”。答案来自系统:来自目录、协议、脚本、测试、评估、观测、审批、清理和文档。
换句话说,未来的软件工程并不会因为模型变强而变得更虚。恰恰相反,它会变得更像工程。
只是工程师手里调的,不再只是代码本身,而是模型与现实之间那层决定成败的编排结构。
如果你今天就想开始,请不要先问:
“我该怎么让 AI 一次写完整个项目?”
先问这个问题:
“如果这个智能体要在我的系统里连续工作七天,我准备让它凭什么不把现场搞乱?”
这个问题的答案,就是你的 Harness。
九、一份可以立刻执行的简版清单
如果你想把本文压缩成一个行动列表,就做这 10 件事:
- 把
AGENTS.md改成导航入口,不要写成百科全书。 - 建立
docs/product、docs/architecture、docs/plans三层知识目录。 - 写一个
init.sh,让智能体每次都能用同一种方式启动环境。 - 写一个
verify.sh,把最小验证路径脚本化。 - 维护一份 feature list,让“完成”变成显式状态而不是主观印象。
- 让每轮任务只推进一个明确目标,并要求留下进度记录。
- 接入浏览器自动化或运行时观测,不要让模型只盯着源码。
- 至少引入一个“评估者”角色,专门负责挑刺。
- 把高风险命令、写操作和合并动作纳入审批策略。
- 固定做文档与代码清理,把熵管理制度化。
如果一支团队真的把这 10 件事做完,哪怕模型本身没有再升级一个大版本,你也会明显感觉到:它不只是“更能写”,而是“更像一个能一起交付的人”。
十、延伸阅读
- Harness engineering: leveraging Codex in an agent-first world
- Unrolling the Codex agent loop
- Unlocking the Codex harness: how we built the App Server
- Effective harnesses for long-running agents
- Harness design for long-running application development
- Effective context engineering for AI agents
- Writing effective tools for agents — with agents
引用
若想引用本文,请使用:
@misc{dong2026harness,
author = {Peijie Dong},
title = {Harness Engineering:把会写代码的模型,变成真正能交付的软件系统},
year = {2026},
month = apr,
day = {15},
howpublished = {\url{https://pprp.github.io/tech/Harness/}},
url = {https://pprp.github.io/tech/Harness/},
note = {Blog post. Accessed: 2026-04-28},
language = {Chinese}
}