GPT-OSS Model Card 解析
核心亮点
gpt-oss-120b
1170亿参数,性能接近 o4-mini
gpt-oss-20b
210亿参数,16GB内存即可运行
智能体功能
函数调用、网页浏览、代码执行
混合专家架构
先进的MoE设计,高效参数利用
API兼容
与OpenAI API完全兼容
本地部署
隐私保护,低延迟推理
1. 模型概览与核心定位
1.1 发布背景与战略意义
2025年8月6日,OpenAI 宣布推出其最新的开源模型系列——GPT-OSS(GPT Open Source Software),标志着这家在人工智能领域长期处于领先地位的公司,在时隔六年之后,再次向开源社区迈出了重大一步[24]。此次发布的模型是自2019年GPT-2以来,OpenAI首次公开发布开放权重的语言模型,这一举动在业界引起了广泛关注和热烈讨论[22]。
OpenAI首席执行官山姆·奥尔特曼(Sam Altman)
"数十亿美元研究的成果"
性能可与公司自家的闭源模型相媲美,同时能够在本地设备上运行
此次开源行动被广泛解读为对当前AI领域竞争格局的直接回应,特别是面对Meta的Llama系列、Mistral AI以及中国初创公司DeepSeek等在开源模型领域的激烈竞争[39] [43]。奥尔特曼此前曾承认,OpenAI在开源技术方面"站在了历史的错误一边",而GPT-OSS的发布正是对这一战略的修正和回归[43]。
GPT-OSS的发布不仅仅是技术层面的更新,更体现了OpenAI在商业化与开放生态之间寻求平衡的尝试[42]。通过提供高性能的开放权重模型,OpenAI旨在赋能从个人开发者到大型企业乃至政府机构的广泛用户群体,使他们能够在自有基础设施上运行、定制和构建AI应用[21]。
1.2 模型系列:gpt-oss-120b 与 gpt-oss-20b
gpt-oss-120b
2. 技术规格与架构创新
2.1 核心架构:混合专家 (MoE) 模型
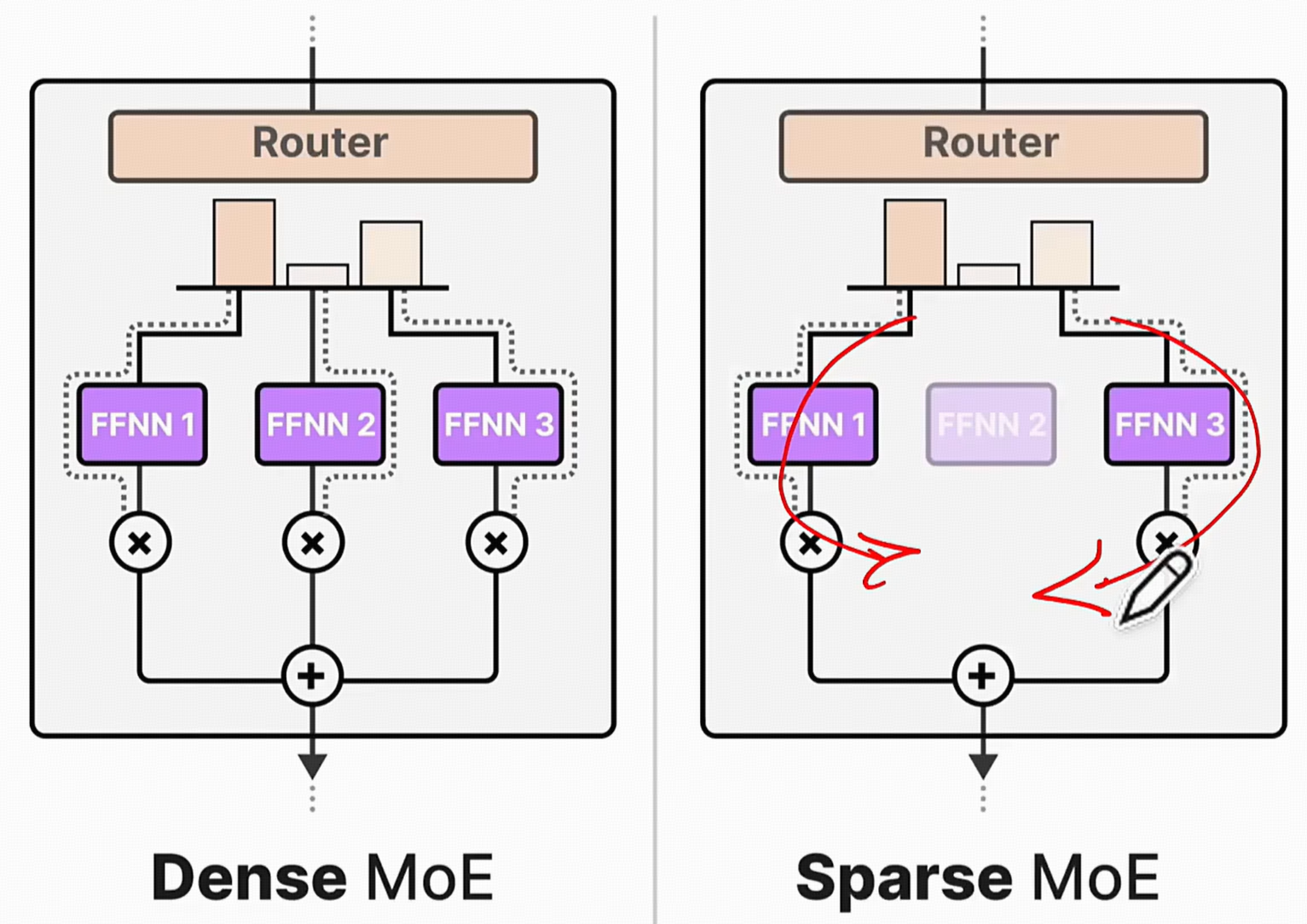
2.2 注意力机制优化
2.3 位置编码与上下文长度
3. 性能表现与基准测试
3.1 推理能力评估
3.2 关键基准测试成绩
3.3 推理速度与效率
4. 功能特性与应用场景
4.1 核心功能
4.2 智能体 (Agentic) 能力
4.3 API 兼容性
5. 部署方式与硬件要求
5.1 本地部署
5.2 云端部署
GPT-OSS 架构概览
117B 参数"] A --> C["gpt-oss-20b
21B 参数"] B --> D["混合专家架构
MoE with 128 Experts"] C --> E["混合专家架构
Optimized for Efficiency"] D --> F["Transformer 36层
Top-4 路由"] E --> G["轻量级设计
16GB 内存需求"] F --> H["128k 上下文窗口
RoPE 位置编码"] G --> H H --> I["分组多查询注意力
Grouped Query Attention"] I --> J["交替注意力机制
密集+稀疏混合"] J --> K["智能体能力
函数调用/网页浏览"] K --> L["API 兼容性
OpenAI Responses API"] style A fill:#e8f4fd,stroke:#1e40af,stroke-width:3px,color:#1e293b style B fill:#fef3c7,stroke:#f59e0b,stroke-width:3px,color:#92400e style C fill:#dcfce7,stroke:#10b981,stroke-width:3px,color:#065f46 style D fill:#fce7f3,stroke:#ec4899,stroke-width:2px,color:#831843 style E fill:#fce7f3,stroke:#ec4899,stroke-width:2px,color:#831843 style F fill:#f3e8ff,stroke:#8b5cf6,stroke-width:2px,color:#5b21b6 style G fill:#f3e8ff,stroke:#8b5cf6,stroke-width:2px,color:#5b21b6 style H fill:#e8f5e8,stroke:#059669,stroke-width:2px,color:#064e3b style I fill:#fff1f2,stroke:#f43f5e,stroke-width:2px,color:#9f1239 style J fill:#fff1f2,stroke:#f43f5e,stroke-width:2px,color:#9f1239 style K fill:#f8fafc,stroke:#64748b,stroke-width:2px,color:#334155 style L fill:#f8fafc,stroke:#64748b,stroke-width:2px,color:#334155
结论
GPT-OSS系列的发布标志着OpenAI在时隔六年后重返开源社区,为AI领域带来了两个高性能的混合专家模型。gpt-oss-120b以接近o4-mini的性能树立了开源模型的新标杆,而gpt-oss-20b则以出色的性价比让先进AI技术能够在消费级设备上运行。
通过Apache 2.0许可证、完整的智能体能力、API兼容性以及灵活的部署选项,GPT-OSS不仅为开发者提供了强大的工具,更为AI技术的普惠化和创新应用开辟了新的可能性。无论是本地隐私计算、专业领域定制,还是边缘设备应用,GPT-OSS都展现了其在新时代AI生态系统中的重要价值。