DeepSeek-V4 论文解读:百万 Token 上下文不是窗口竞赛,而是系统工程
DeepSeek-V4 Paper Notes: Million-Token Context as Systems Engineering
这篇文章基于论文《DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence》和原始中文整理稿重写。它不是逐段翻译,而是把论文重新组织成一条更适合阅读的技术主线:为什么百万 token 上下文困难,DeepSeek-V4 怎么把它做得更便宜,以及这些设计对长程 agent 和 test-time scaling 意味着什么。
先说结论:真正的问题不是 1M 窗口,而是 1M 窗口能不能被用得起
如果只看标题,DeepSeek-V4 最容易被理解成又一个“支持 100 万 token 上下文”的模型。
但这篇论文真正值得读的地方,不是窗口长度本身,而是它把百万 token 上下文重新定义成一整套协同问题:注意力怎么降复杂度,KV cache 怎么压,长前缀怎么复用,MoE 通信怎么隐藏,低精度怎么进入训练和推理,post-training 又如何让模型真的会用长上下文做 agent 任务。
论文发布的是 DeepSeek-V4 系列预览版,包括两个 MoE 模型:
| 模型 | 总参数 | 每 token 激活参数 | 上下文长度 |
|---|---|---|---|
| DeepSeek-V4-Pro | 1.6T | 49B | 1M tokens |
| DeepSeek-V4-Flash | 284B | 13B | 1M tokens |
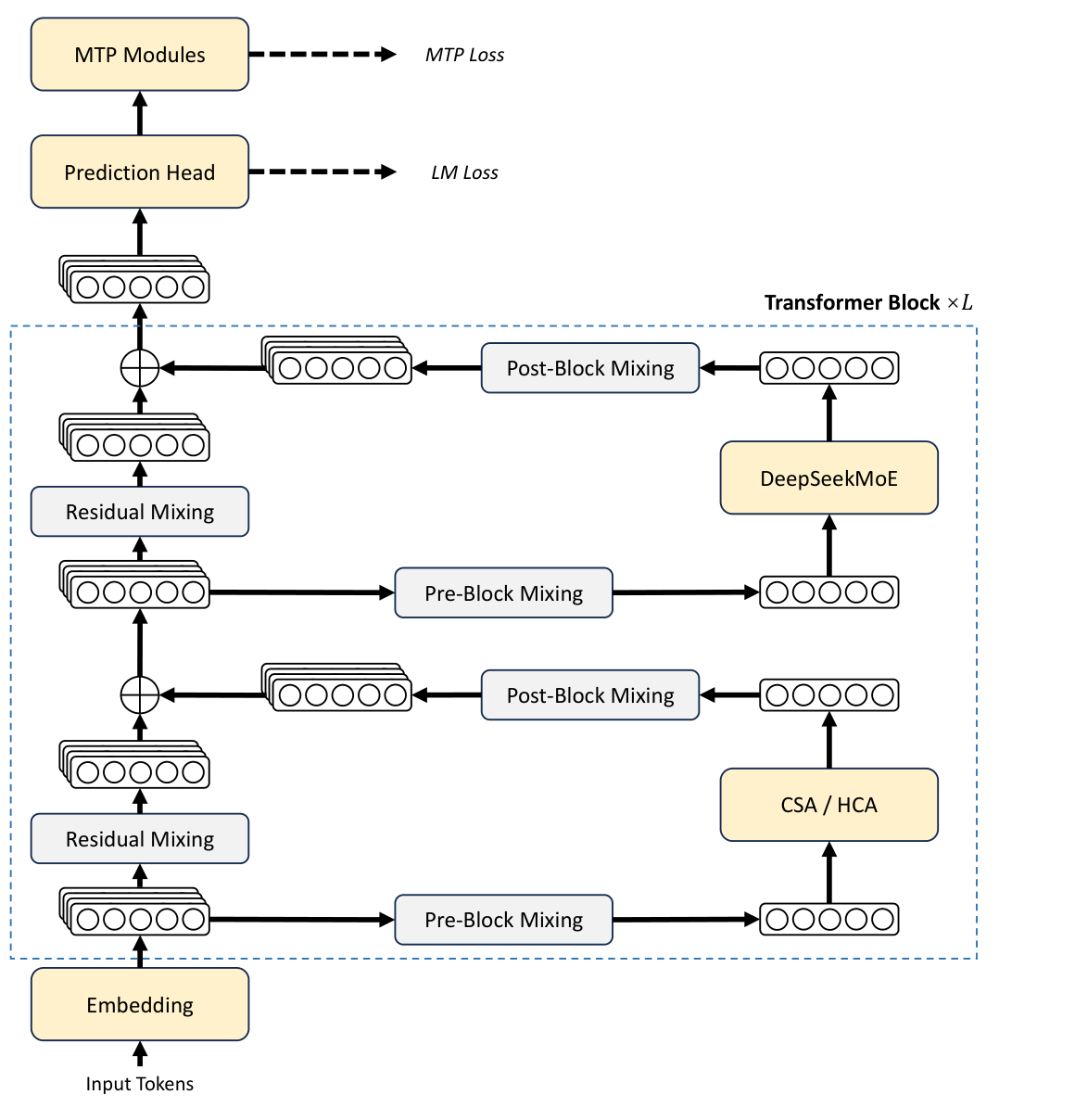
图 1. 论文 Figure 2:DeepSeek-V4 保留 Transformer、DeepSeekMoE 和 MTP,同时把注意力层替换为 CSA/HCA,并用 mHC 强化 residual mixing。
论文给出的核心效率数字很直接。在 1M token 上下文下,相比 DeepSeek-V3.2,DeepSeek-V4-Pro 的单 token 推理 FLOPs 约为 27%,KV cache 约为 10%;DeepSeek-V4-Flash 更激进,单 token 推理 FLOPs 约为 10%,KV cache 约为 7%。
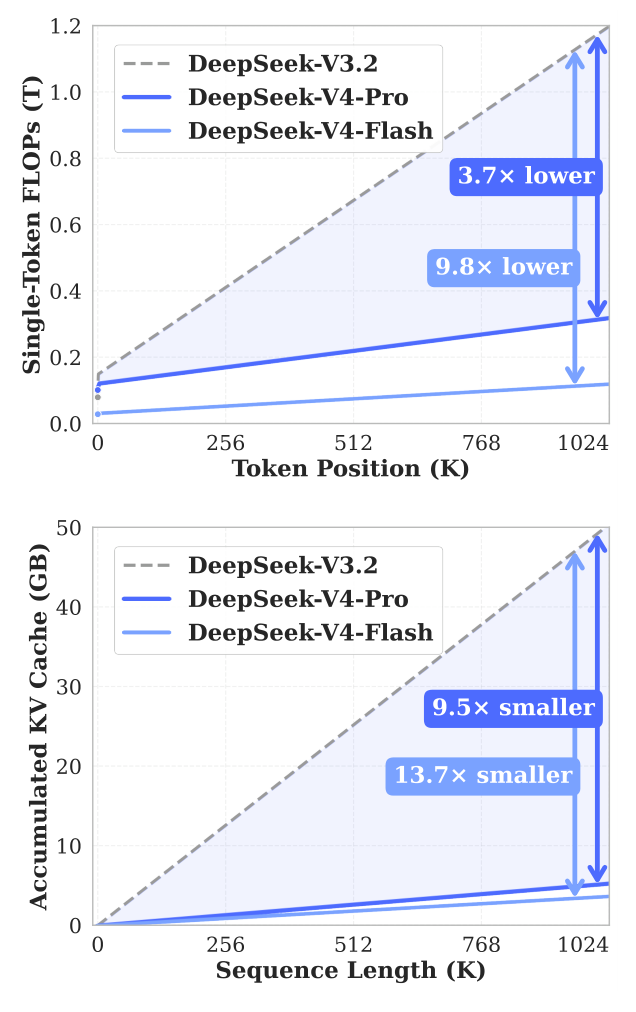
图 2. 论文首页右侧效率曲线:DeepSeek-V4-Pro 和 Flash 在 1M token 位置相对 DeepSeek-V3.2 明显降低单 token FLOPs 与累计 KV cache。
所以 DeepSeek-V4 的核心问题意识不是“我能不能看到更长历史”,而是:
当模型被要求持续读、持续想、持续调用工具时,能不能把长上下文的成本压到可训练、可部署、可复用的范围内?
这个问题比单纯扩大 context window 更难。因为上下文长度一旦进入百万级,瓶颈会同时出现在计算、显存、带宽、缓存布局、分布式训练和 agent runtime 里。换句话说,百万上下文不是一个模型参数,而是一条服务链路。
百万上下文首先是 serving 问题,而不是论文标题里的窗口数字
标准 Transformer 的注意力有两个经典麻烦。
第一,attention 计算会随序列长度快速增长。越长的上下文,不只是多读一点文本,而是每个新 token 都要和庞大的历史发生关系。
第二,KV cache 会随上下文长度线性膨胀。对普通聊天来说,线性增长已经让服务成本变贵;对 1M token、长程工具调用、代码仓库分析和多轮 agent 任务来说,它会变成吞吐和显存预算里的硬约束。
DeepSeek-V4 的论文把这个问题放在 test-time scaling 的背景下讨论。推理模型之所以越来越强,很大一部分来自推理时投入更多计算:更长的思考链、更复杂的搜索、更频繁的工具调用、更长的中间轨迹。但如果 attention 和 KV cache 的成本跟不上,这条 scaling 路线就会被上下文系统卡住。
所以 DeepSeek-V4 的主线不是“把窗口拉长”,而是“把长窗口背后的成本链路拆开重做”。可以画成这样:
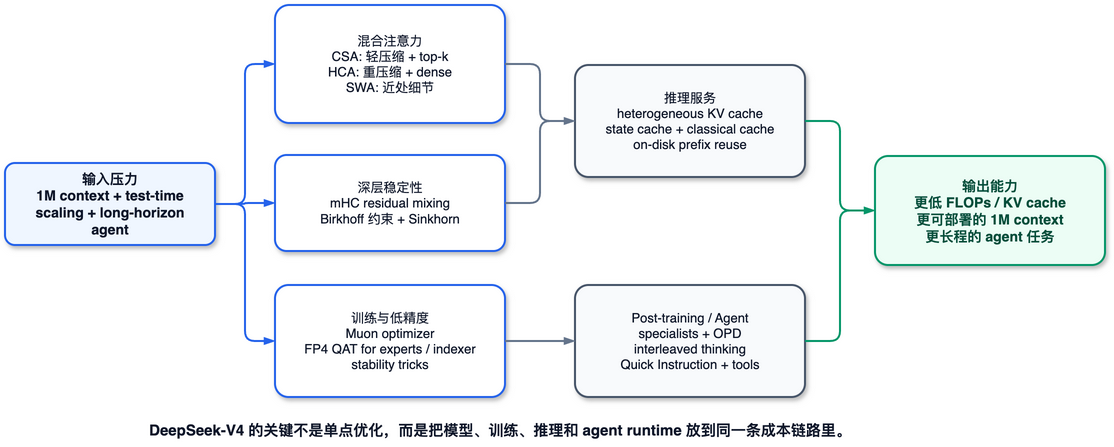
图 3. 自绘示意图:DeepSeek-V4 的核心不是单点优化,而是把模型架构、训练稳定性、低精度、推理缓存和 agent post-training 放在同一条成本链路里。对应 draw.io 源文件保存在 images/deepseek-v4/deepseek-v4-system-stack.drawio。
这张图里最重要的是中间两条线:DeepSeek-V4 不是只在模型架构上动刀,也在 serving cache、kernel、通信和 post-training 上同时做配套。它的技术判断很清楚:如果状态不能被便宜地保存、复用和验证,长上下文本身就很难变成稳定产品能力。
CSA 与 HCA:不是一种注意力打天下,而是分辨率分工
论文最核心的架构贡献是混合注意力:Compressed Sparse Attention,简称 CSA;以及 Heavily Compressed Attention,简称 HCA。
可以先用一个直觉来理解:百万 token 不是所有位置都值得同等精度访问。模型需要一部分机制保留远程细节,也需要另一部分机制低成本扫过全局背景。CSA 更像“压缩后检索精读”,HCA 更像“高度压缩后全局粗读”。
| 组件 | 基本做法 | DeepSeek-V4 配置 | 主要作用 |
|---|---|---|---|
| CSA | 每 m 个 token 压缩成一个 KV entry,再做 top-k 稀疏选择 | m = 4;Flash top-k = 512;Pro top-k = 1024 | 保留较细粒度的远程依赖 |
| HCA | 每 m’ 个 token 高度压缩成一个 KV entry,在压缩序列上做 dense attention | m’ = 128 | 便宜地建模全局粗粒度信息 |
| SWA 分支 | 额外关注最近未压缩 token | window = 128 | 补回局部精细细节 |
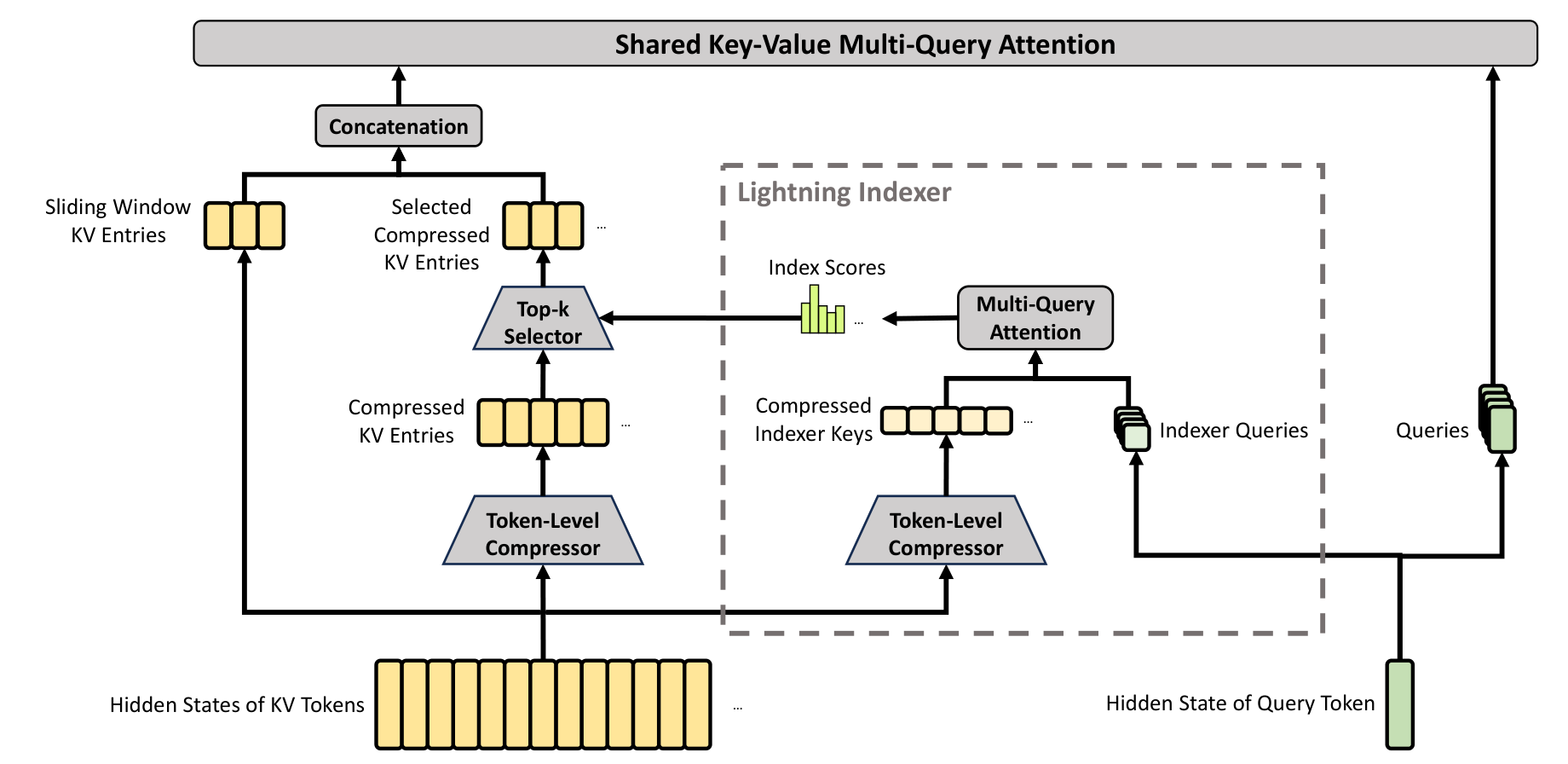
图 4. 论文 Figure 3:CSA 先做 token-level compression,再用 Lightning Indexer 选出 top-k compressed KV entries,最后和 sliding window KV 一起进入 shared key-value MQA。
CSA 的流程分三步。
先做 KV 压缩。它不是简单平均,而是学习 KV 分支和权重,把连续 token 组合成 compressed entries。论文还使用重叠压缩,让一个 compressed entry 能参考相邻 block 的信息,减少硬切分带来的局部断裂。
然后用 Lightning Indexer 选 top-k。压缩后的 KV entries 仍然很多,所以 CSA 不对所有 compressed entries 做 attention,而是让轻量 indexer 先为当前 query 找出最相关的一小部分。这一步很像把 attention 变成“先检索,再注意”。
最后执行 shared key-value MQA。这里 compressed KV entry 同时作为 key 和 value,KV 在多个 query head 间共享,从而继续降低 KV cache 和计算成本。因为 query head 多、head dimension 大,论文还加入 grouped output projection,先分组投影再合并,避免输出投影本身变成新瓶颈。
HCA 则更极端。它不再做 top-k sparse selection,而是把每 128 个 token 压成一个 KV entry,然后在高度压缩后的序列上做 dense attention。这样模型仍然能低成本访问全局信息,只是分辨率更粗。
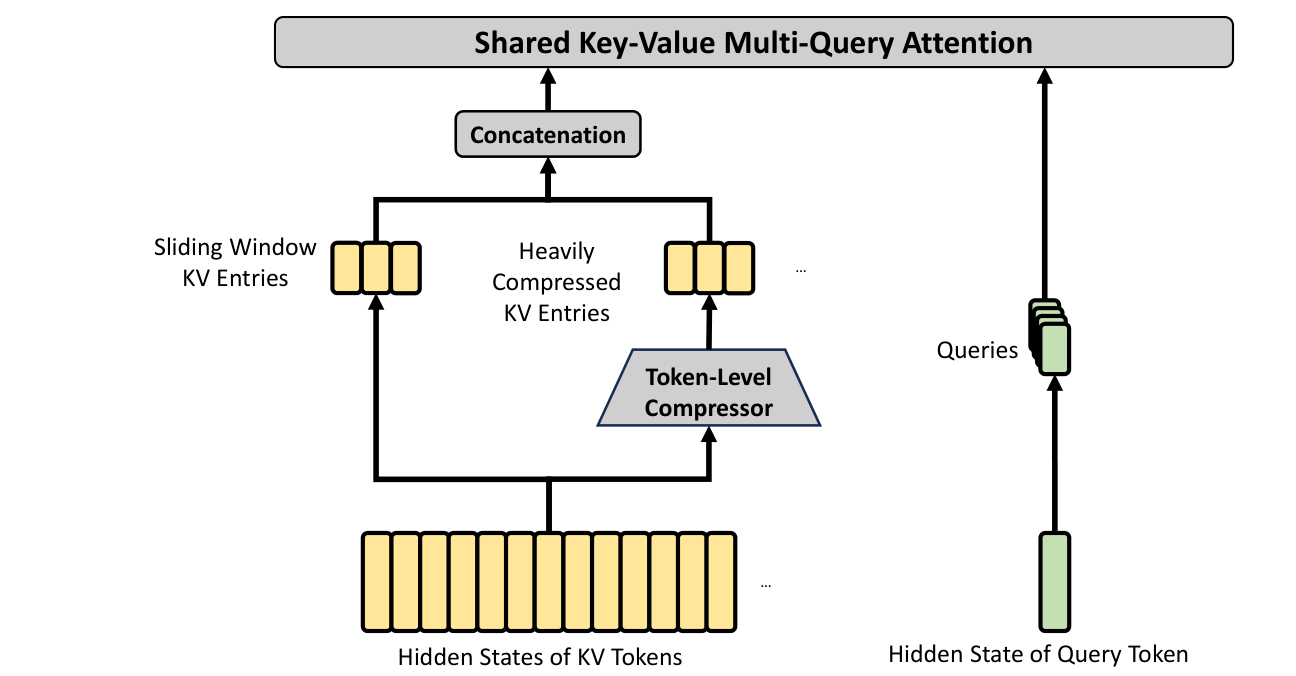
图 5. 论文 Figure 4:HCA 用更高压缩率换取全局 dense attention 的低成本版本,同时仍保留最近窗口的未压缩 KV。
真正有意思的是,DeepSeek-V4 没有把 CSA 或 HCA 当成单独答案,而是把它们交错使用。CSA 负责较精细的长程依赖,HCA 负责便宜的全局背景,SWA 再补足最近窗口里的未压缩细节。这个组合说明论文作者并不相信“单一稀疏策略”足够覆盖所有长上下文需求。
压缩不是免费午餐:局部细节必须被单独保护
只做压缩会有一个明显副作用:query 可能无法访问同一个压缩 block 内还没进入 compressed entry 的 token,也可能丢掉局部顺序里的细微差别。
DeepSeek-V4 的处理方式是额外加入 sliding window attention 分支,让每个 query 能继续关注最近 128 个未压缩 token。这样模型同时拥有两种记忆:
| 记忆类型 | 信息粒度 | 成本形态 |
|---|---|---|
| 压缩长程记忆 | 较粗或稀疏的远程信息 | 随压缩率和 top-k 控制 |
| 滑窗局部记忆 | 最近 token 的精细信息 | 固定窗口成本 |
这个设计很工程化。长文档理解、代码仓库分析和工具轨迹里,很多全局信息只需要知道“哪里可能相关”,但局部编辑、函数签名、错误日志尾部、最近工具返回值又必须保留细节。CSA/HCA 加 SWA 的组合,本质上是在把“远处粗看、近处细看”写进注意力结构里。
论文还加了几处稳定性细节。Query 和 compressed KV entries 在 attention 前做 RMSNorm,用来控制 logits;RoPE 只施加在最后 64 维,并对输出做反向位置旋转,避免 compressed KV 同时作为 key/value 时把不合适的绝对位置信息带入输出;attention sink 则给每个 head 一个可学习的 sink logit,让模型在某些 token 不需要强行关注上下文时有更大的自由度。
这些细节单看都不夸张,但放在一起说明一件事:压缩注意力不是简单把序列缩短,它会改变位置编码、归一化、输出投影、局部访问和 cache layout 的整体假设。
mHC:当注意力变复杂,残差通路也要重新设计
除了 attention,DeepSeek-V4 还引入 Manifold-Constrained Hyper-Connections,简称 mHC,用来增强传统 residual connection。
普通 Transformer 的 residual stream 可以理解成一条宽度为 d 的信息通道。Hyper-Connections 会把它扩展成 n_hc x d,DeepSeek-V4 中 n_hc = 4。每一层不再只是在一条 residual stream 上读写,而是通过输入映射、状态转移矩阵和输出映射,在扩展 residual stream 中混合和写回信息。
论文给出的更新形式可以简化理解为:
[ X_{l+1} = B_l X_l + C_l F_l(A_l X_l) ]
这里 A_l 决定当前层从扩展 residual stream 中读什么,F_l 是这一层的主体变换,C_l 决定输出怎么写回,B_l 则控制 residual state 自身怎么流动。
mHC 的关键不是“多一条残差”,而是把 B_l 约束到 Birkhoff polytope,也就是双随机矩阵集合:每行、每列和都为 1,元素非负。这样做的直觉是让 residual 状态转移变成 non-expansive,不轻易放大信号,从而在深层堆叠时更稳定。
实现上,论文使用 Sinkhorn-Knopp 迭代把 unconstrained matrix 投影到双随机矩阵流形,DeepSeek-V4 中迭代次数设为 20。A_l 和 C_l 也通过 Sigmoid 保持非负和有界,进一步减少不稳定的信号抵消。
如果说 CSA/HCA 解决的是“长上下文太贵”,mHC 解决的就是“这么复杂、这么深的模型怎么稳定传递信息”。这也是 DeepSeek-V4 论文的一个特点:它不是只讨论推理效率,也把训练稳定性和深层表达能力放进了同一套设计里。
Muon、FP4 与训练稳定性:效率不只发生在推理期
DeepSeek-V4 大部分参数使用 Muon optimizer,少数敏感模块继续使用 AdamW,例如 embedding、prediction head、mHC 的静态 bias 和 gating factors、RMSNorm 权重。
Muon 的核心思想是对梯度动量矩阵做近似正交化。论文采用 Nesterov trick 和 hybrid Newton-Schulz iteration:前 8 步使用更激进的系数快速逼近,后 2 步使用稳定系数精细收敛。DeepSeek-V4 没有使用 QK-Clip,因为注意力结构本身已经在 query 和 KV 上引入 RMSNorm 来控制 logits。
低精度方面,论文在 post-training 阶段引入 FP4 quantization-aware training,主要作用于 MoE expert weights 和 CSA indexer 的 QK path。MoE expert weights 在训练时保留 FP32 master weights,前向中量化到 FP4,再 dequantize 到 FP8 计算;推理和 RL rollout 时直接使用真实 FP4 权重,减少显存和 memory loading。CSA indexer 的 QK path 使用 FP4,则是因为百万上下文下 indexer 自身也会变成显著开销。
训练 trillion-parameter MoE 时还有一个很现实的问题:loss spike。论文把 spike 与 MoE 层 outliers 和 routing 反馈联系起来,提出了两个技巧。
Anticipatory Routing 使用历史参数提前计算 routing indices,打破 backbone 和 routing network 同步更新造成的不稳定反馈。SwiGLU Clamping 则把 linear component 限制在 [-10, 10],把 gate component 上界限制为 10,用数值裁剪抑制 outliers。
论文也承认,这些稳定性机制有效,但底层原理仍没有完全解释清楚。这点反而很重要:DeepSeek-V4 的许多设计是系统工程和经验科学共同推进的结果,不是每个 trick 都已经有漂亮理论。读这类论文时,不能只找“一个决定性发明”,更要看这些经验性约束如何共同把训练推过不稳定区。
KV cache:从普通分页缓存,走向异构状态管理
DeepSeek-V4 的推理系统不能直接套传统 PagedAttention,因为它的 cache 结构已经不再是每层同质、每 token 同尺寸的普通 KV。
论文把 KV cache 分成两类。第一类是 classical KV cache,用来存 CSA/HCA 的 compressed KV。第二类是 state cache,用来存 sliding window attention 的 KV,以及 CSA/HCA 中还没凑满 compression block 的尾部未压缩状态。
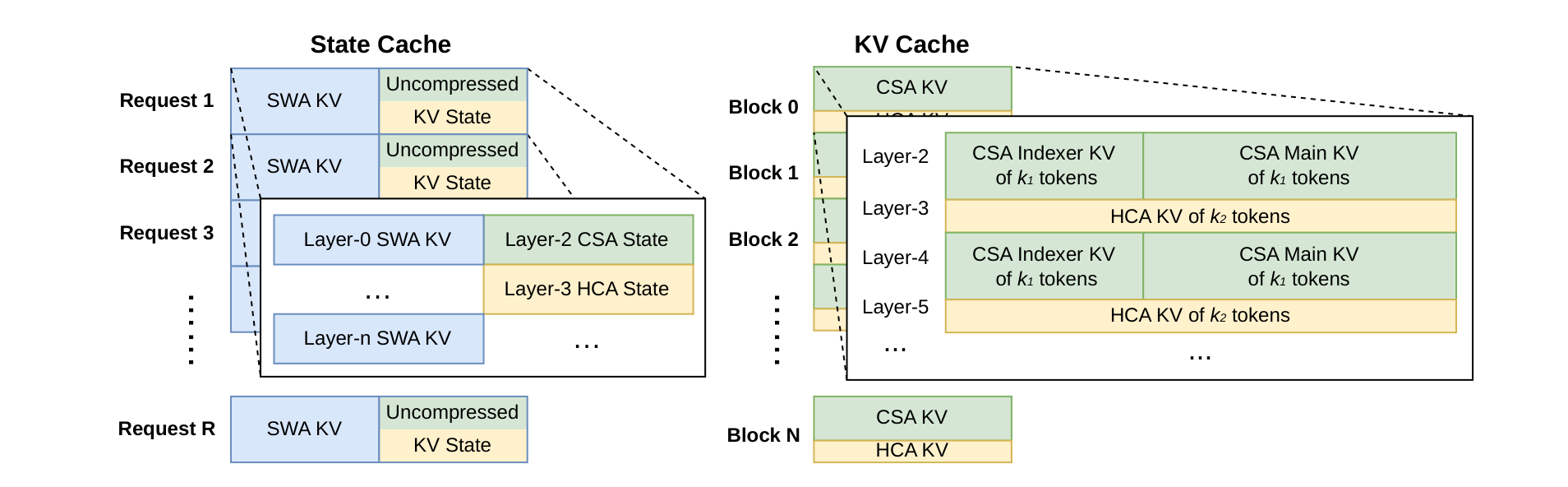
图 6. 论文 Figure 6:DeepSeek-V4 把 cache 拆成 state cache 和 classical KV cache,前者负责 SWA 与未压缩尾部状态,后者负责 CSA/HCA 的压缩 KV。
这个划分很关键。SWA 和未完成压缩的 tail states 更像 sequence-specific state,只依赖当前位置,需要固定大小的状态池动态分配;CSA/HCA 的 compressed KV 则更像长前缀缓存,可以按压缩 block 管理,并与 sparse attention kernel 做联合设计。
为了服务共享长前缀请求,DeepSeek-V4 还使用 on-disk KV cache。对 CSA/HCA 来说,系统可以把 compressed KV entries 存下来,命中共享前缀时直接读取完整 compression block 对应的 cache,尾部不完整 block 再重算。对 SWA,论文讨论了 full caching、periodic checkpointing 和 zero caching 三种策略,在写入量和重算成本之间取舍。
这部分非常值得关注,因为它说明百万上下文的瓶颈已经从“模型能不能算”延伸到了“服务系统能不能复用状态”。长上下文如果每次都完整 prefill,很多理论能力会在成本上失去意义;只有 cache layout、磁盘缓存、prefix reuse 和 kernel 对齐一起成立,1M context 才更接近可用产品能力。
系统工程:真正难的是让复杂架构稳定跑起来
DeepSeek-V4 论文第三章花了大量篇幅讲 infrastructure,这不是附录式内容,而是模型设计能成立的前提。
MoE expert parallelism 的核心瓶颈是 dispatch/combine 的 all-to-all 通信。DeepSeek-V4 把专家切成多个 wave,形成细粒度流水线:当前 wave 计算、下一 wave token transfer、上一 wave result sending 并行进行,并融合成单个 mega-kernel。论文报告该方案在一般推理 workload 上带来 1.50-1.73x 加速,在 RL rollout 或高速 agent serving 等低延迟场景最高 1.96x。
Kernel 开发上,论文使用 TileLang 来写 fused kernels。它的价值不是单纯替代 CUDA,而是在大量细粒度操作存在时,提高开发效率并减少 PyTorch ATen 调用带来的 kernel invocation overhead。论文还强调了 host codegen、SMT solver 辅助整数分析,以及默认关闭 fast-math 来保证数值精度和 bitwise reproducibility。
可复现性也被系统性处理。DeepSeek-V4 开发了 batch-invariant 和 deterministic kernel 库,让同一个 token 的输出不受 batch 位置影响,并减少 atomicAdd、浮点归约顺序等因素带来的不确定性。这对大规模训练 debug 很重要,因为 loss spike、硬件错误和数值异常如果不能复现,排查成本会迅速失控。
训练框架还做了三类适配:Muon 与 ZeRO 的兼容、mHC 的低成本实现、压缩注意力下的 context parallelism。尤其是最后一点,CSA/HCA 的 compression block 可能跨 rank 边界,不能直接套传统 context parallelism。论文采用两阶段通信,让每个 rank 交换边界 KV,再 all-gather compressed KV,并通过 fused select-and-pad 重排。
这些内容读起来不像“模型能力”,但它们决定了模型能力能不能以合理成本落地。长上下文模型越往百万级走,论文里的系统章节就越不是配角,而是能力本身的一部分。
Post-training:窗口很长不等于 agent 真会用
DeepSeek-V4 的 post-training 主线是两阶段:先训练多个 domain-specific specialists,再用 On-Policy Distillation,简称 OPD,把专家能力合并进一个统一模型。
专家训练阶段覆盖数学、编程、agent、instruction following、hard-to-verify tasks 等领域,流程是 SFT 后接 GRPO。DeepSeek-V4-Pro 和 Flash 都支持三种 reasoning effort:Non-think、Think High 和 Think Max。区别不只是提示词,而是 RL 训练中使用不同的 length penalty 和 context window,让模型学会在不同推理预算下工作。
OPD 的关键点是“on-policy”。学生模型在自己生成的 trajectories 上学习多个专家模型的分布,用 reverse KL 做 logits-level alignment。论文认为,传统 token-level KL 近似虽然省资源,但梯度方差高、训练不稳定,所以 DeepSeek-V4 使用 full-vocabulary logit distillation,并通过 teacher weight offload、last-layer hidden state caching、按 teacher index 排序 mini-batch 和 TileLang KL kernel 来降低成本。
另外几个 agent 相关细节也很有意思。
首先是 Generative Reward Model。DeepSeek-V4 不再只依赖传统 scalar reward model,而是让 actor model 自身也承担 judge 角色,通过 rubric-guided RL data 训练评价能力。这样模型的推理能力会进入打分过程,对 hard-to-verify tasks 更友好。
其次是工具调用格式。论文引入 |DSML| special token 和 XML-like tool call schema,目标是减少 escaping failures 和 tool-call errors。对 agent 来说,工具协议的稳定性不是小事;格式错误会直接中断轨迹。
第三是 interleaved thinking。DeepSeek-V4 在工具调用场景中保留完整 reasoning content,包括跨用户消息边界的思考轨迹,以支持长程 agent task;普通对话场景则沿用更简洁的策略,新用户消息到来后丢弃旧 thinking content。也就是说,它把“是否保留推理轨迹”变成与场景绑定的上下文管理策略。
最后是 Quick Instruction。搜索触发、query 生成、权威性判断、domain 判断、URL 是否读取、标题生成这类辅助任务,传统上可能交给小模型,但小模型不能复用主模型已有 KV cache。DeepSeek-V4 用特殊 token 直接在同一大模型里执行这些辅助判断,复用已有 cache,降低 time-to-first-token,也减少维护额外小模型的工程负担。
评测结果怎么读:看排名,更要看能力边界
评测部分需要带一个前提:下面数字来自论文作者报告,不等同于第三方独立复现。它们适合用来理解论文主张和模型定位,但不应该被当作严格同场、公证后的最终结论。
Base 模型对比里,V4-Flash-Base 虽然只有 13B 激活参数、284B 总参数,但在不少任务上超过 DeepSeek-V3.2-Base。V4-Pro-Base 则在知识、推理、代码和长上下文上整体成为 DeepSeek 系列更强 base model。几个代表性数字如下:
| Benchmark | V3.2-Base | V4-Flash-Base | V4-Pro-Base |
|---|---|---|---|
| MMLU-Pro | 65.5 | 68.3 | 73.5 |
| SimpleQA verified | 28.3 | 30.1 | 55.2 |
| FACTS Parametric | 27.1 | 33.9 | 62.6 |
| LongBench-V2 | 40.2 | 44.7 | 51.5 |
Post-training 后,DeepSeek-V4-Pro-Max 在论文表 6 中被拿来和 Claude Opus 4.6、GPT-5.4、Gemini-3.1-Pro、Kimi K2.6、GLM-5.1 等模型比较。它在开放模型中表现很强,在一些推理和代码竞赛指标上接近或超过表中模型,例如 LiveCodeBench 93.5、Codeforces rating 3206、Apex Shortlist 90.2。
长上下文方面,DeepSeek-V4-Pro-Max 在 LongMRCR 1M 上为 83.5,低于 Opus 4.6 的 92.9,高于 Gemini-3.1-Pro 的 76.3;CorpusQA 1M 为 62.0,低于 Opus 4.6 的 71.7,高于 Gemini-3.1-Pro 的 53.8。论文的 MRCR 曲线还显示,模型在 128K 以内比较稳定,超过 128K 后性能会下降,但到 1M 仍保持较强检索能力。
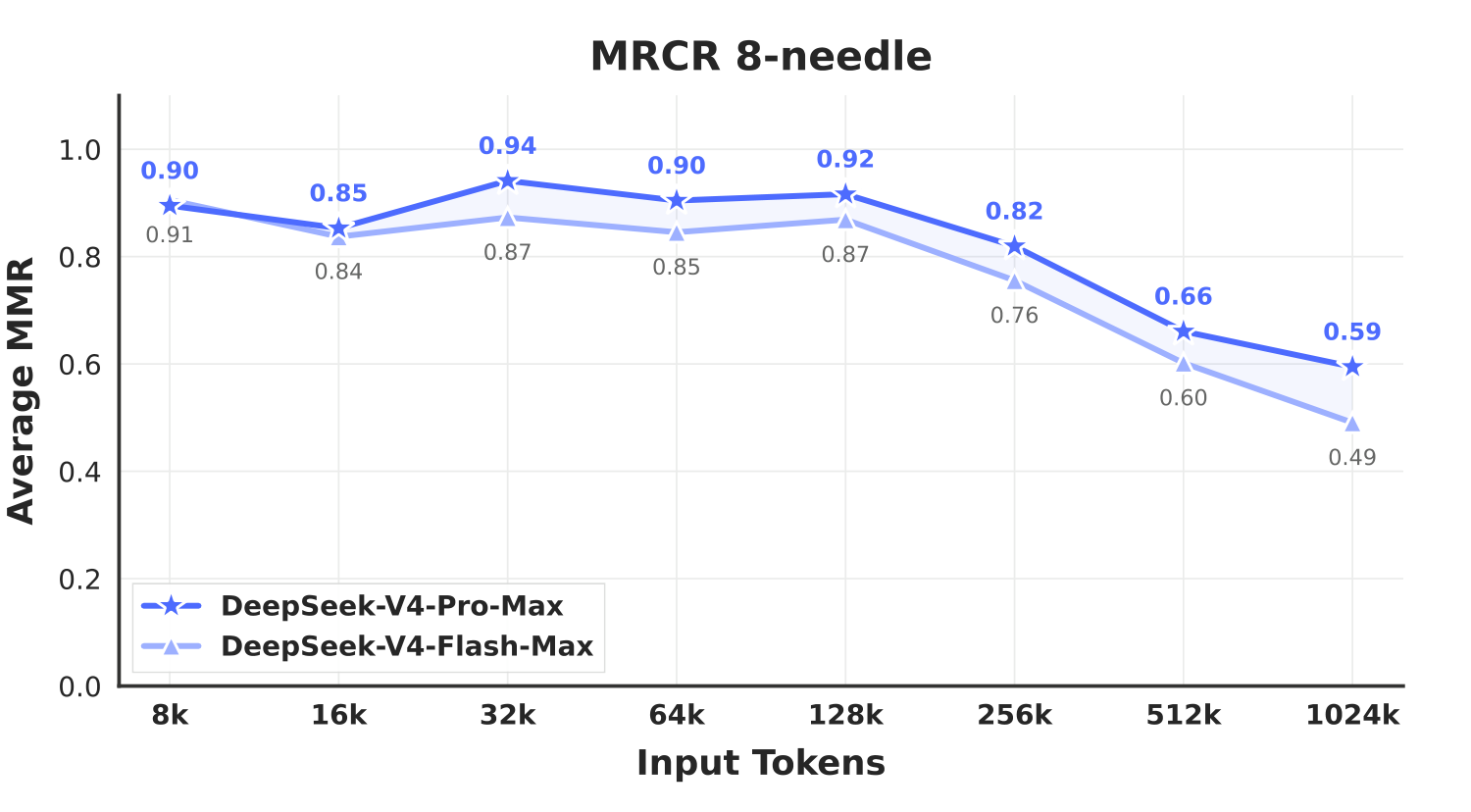
图 7. 论文 Figure 9:MRCR 8-needle 曲线显示,V4-Pro-Max 和 V4-Flash-Max 在 128K 以内较稳定,超过 128K 后逐步下降,但 1M 位置仍保留可观检索能力。
Agent 任务的结果更接近“可用但仍有差距”的叙事。SWE Verified 上 DeepSeek-V4-Pro-Max 为 80.6,与 Gemini-3.1-Pro 的 80.6 相同,接近 Opus 4.6 的 80.8;Terminal Bench 2.0 为 67.9,低于 GPT-5.4 的 75.1,接近 Gemini-3.1-Pro 的 68.5。内部 R&D coding benchmark 中,论文报告 DeepSeek-V4-Pro-Max pass rate 为 67%,低于 Opus 4.5 Thinking 的 73% 和 Opus 4.6 Thinking 的 80%,但高于 Sonnet 4.5 的 47%。
Flash 和 Pro 的差异也很清楚:知识任务更依赖参数规模,Pro 优势明显;数学和代码推理中,Flash 在更大 thinking budget 下可以接近 Pro;复杂 agent 任务上,Pro 仍然更稳。这个差异提醒我们,长上下文只是底座,最终能力仍然受到参数规模、训练分布、推理预算和工具环境共同约束。
局限性:系统性越强,复现和维护成本也越高
DeepSeek-V4 最值得肯定的是系统性,但它最大的风险也来自系统性。
第一,架构复杂度很高。CSA、HCA、SWA、mHC、FP4、Muon、异构 KV cache、on-disk cache、OPD 和 sandbox infrastructure 全部叠在一起,能力和效率来自协同,也意味着理解、复现、维护和迁移都更难。
第二,一些训练稳定性技巧还缺少理论解释。Anticipatory Routing 和 SwiGLU Clamping 有效,但论文也承认背后的机制仍需进一步研究。
第三,长上下文不是无损魔法。MRCR 曲线显示,超过 128K 后性能仍会下降。1M context 能保持较强能力很重要,但它不等于模型在百万 token 内任意位置都能稳定、等精度地读写信息。
第四,agent 与真实办公任务仍有明显改进空间。论文自己的评估也指出,复杂指令遵循、格式美学、slide 视觉呈现、模糊 prompt 理解和偶尔过度思考都还存在问题。
最后:DeepSeek-V4 的真正信号,是长上下文正在变成系统工程
DeepSeek-V4 最像一次从“长上下文模型”到“长上下文系统”的升级。
它的核心不是某个单点发明,而是把多个层面的成本同时压下来:CSA/HCA 压 attention,SWA 保局部细节,mHC 稳定深层残差,Muon 和 FP4 改善训练与推理效率,定制 KV cache 支持百万上下文 serving,OPD 合并专家能力,DSec sandbox 和 rollout service 支撑真实 agent 数据。
如果只关心模型榜单,这篇论文可以读成“DeepSeek 开放模型继续逼近前沿闭源模型”。但更有价值的读法是:
百万 token 上下文的竞争,正在从窗口长度竞争,转向架构、缓存、低精度、训练稳定性、工具协议和 agent runtime 的系统协同竞争。
这也是 DeepSeek-V4 对后续开源模型最重要的启发。长上下文不会只靠更大的 context window 自然变好,它需要模型和系统一起重新设计。未来真正值得比较的,可能不只是“谁的窗口更长”,而是谁能把长程状态以更低成本、更高可靠性、更好工具协议长期维持下去。
引用
若想引用本文,请使用:
@misc{dong2026deepseekv4milliontokencontextzh,
author = {Peijie Dong},
title = {DeepSeek-V4 论文解读:百万 Token 上下文不是窗口竞赛,而是系统工程},
year = {2026},
month = apr,
day = {24},
howpublished = {\url{https://pprp.github.io/tech/deepseek-v4-million-token-context-zh/}},
url = {https://pprp.github.io/tech/deepseek-v4-million-token-context-zh/},
note = {Blog post. Accessed: 2026-04-28},
language = {Chinese}
}