大型语言模型量化技术:原理、前沿与实践
大型语言模型量化技术
通过降低数值精度实现模型压缩与推理加速的核心技术
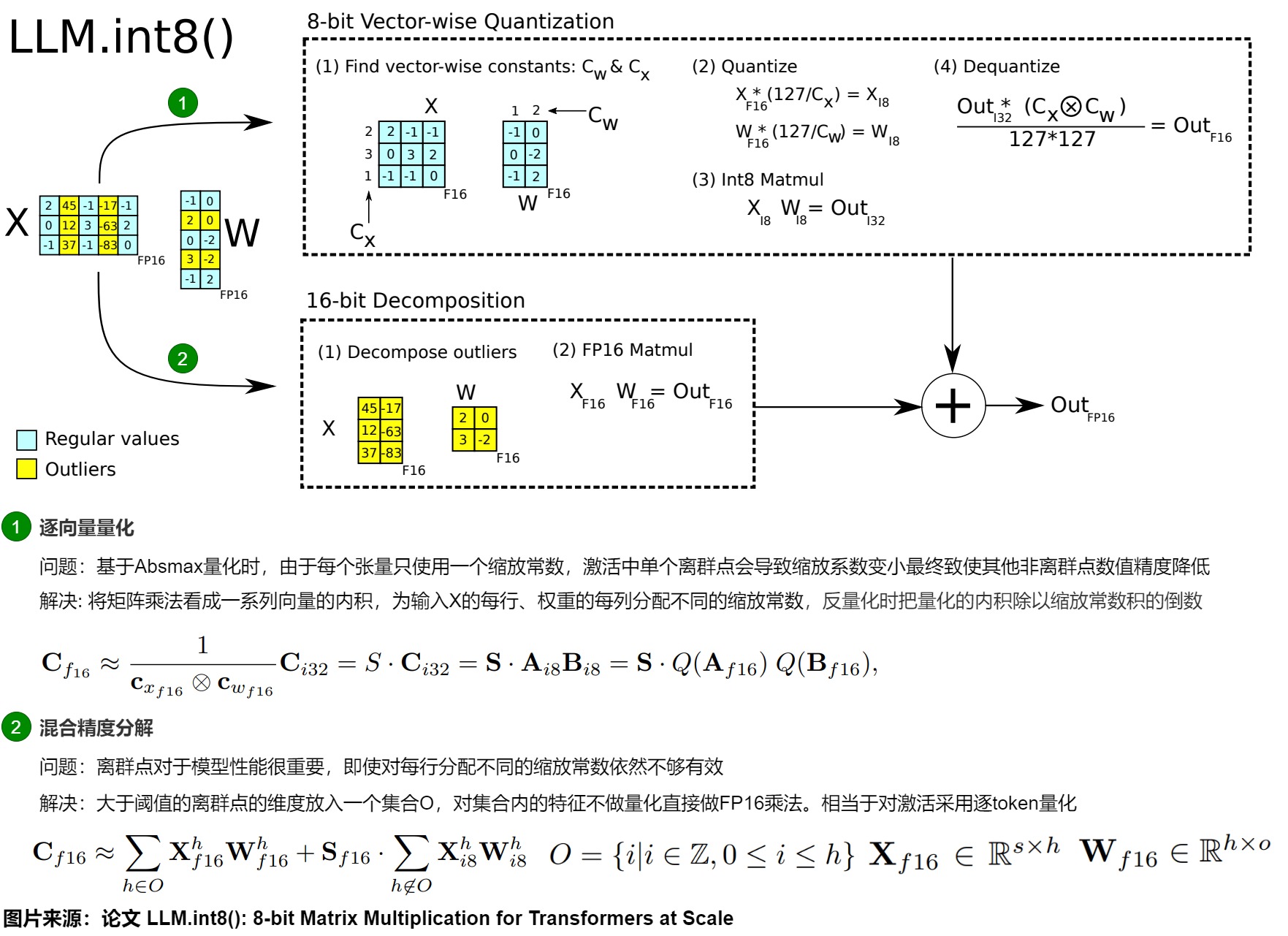
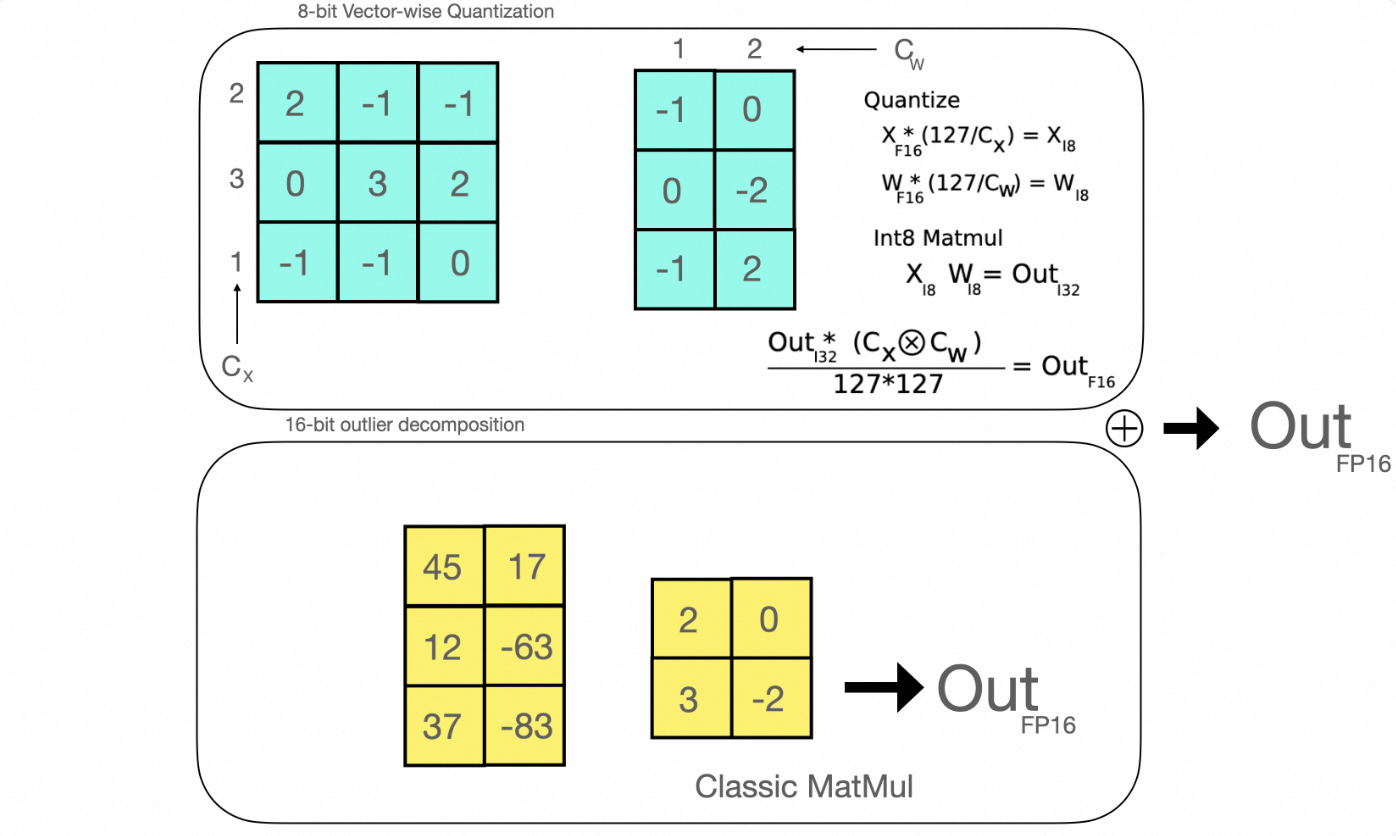
量化技术概述
大型语言模型(LLM)的量化是一种通过降低模型参数数值精度来减小模型尺寸、加速推理并降低内存占用的关键技术。它通过将高精度浮点数(如FP32)映射到低精度整数(如INT8、INT4),在几乎不损失模型性能的前提下,实现显著的效率提升 [1]。
核心技术优势
- • 模型尺寸减少75%-90%
- • 推理速度提升2-4倍
- • 内存占用显著降低
- • 精度损失控制在可接受范围
主流的量化技术包括GPTQ、AWQ和QLoRA,它们分别适用于不同的场景:GPTQ和AWQ是高效的后训练量化(PTQ)方法,适用于快速部署;而QLoRA则是一种结合量化的微调技术,适用于在消费级硬件上对大型模型进行定制化训练 [4]。
量化基本原理与数学基础
对称量化
量化范围以零为中心对称分布,缩放因子计算公式:
- • 零点固定为0,硬件实现简单
- • 适合数据分布对称的场景
- • 计算效率高,推理速度快
非对称量化
直接使用数据的最小值和最大值定义量化范围:
- • 引入零点偏移参数
- • 适合非对称数据分布
- • 量化精度更高
量化与反量化过程
量化过程
- 1. 确定量化范围 [α, β]
- 2. 计算缩放因子 S
- 3. 计算零点 Z(非对称量化)
- 4. 应用量化公式:q = round(x/S) - Z
反量化过程
- 1. 加载量化后的整数 q
- 2. 应用反量化公式:x' = (q + Z) × S
- 3. 恢复为浮点表示
- 4. 继续后续计算
数学本质:量化是在有限精度约束下,寻找最优的离散表示,使得量化误差 ‖x - x'‖ 最小化 [5]。
量化对模型性能的影响与评估
精度损失
4位量化通常带来1-3%的精度下降,可通过先进算法优化
推理加速
低精度计算可提升2-4倍推理速度,减少内存带宽需求
内存优化
模型大小减少75%-90%,显存占用显著降低
主流LLM量化技术深度解析
GPTQ (Generative Pre-trained Transformer Quantization)
基于二阶信息的逐层量化技术
核心原理
- • 逐层处理Transformer线性层
- • 利用Hessian矩阵进行误差补偿
- • 权重矩阵分块量化
- • 最小化输出误差为目标
优缺点分析
高精度,成熟生态系统,适合大型模型
量化速度慢,计算复杂度高
AWQ (Activation-aware Weight Quantization)
基于激活值分布保护关键权重
核心原理
- • 分析激活值分布识别显著权重
- • 通过缩放机制保护关键通道
- • 网格搜索优化缩放因子
- • 数学等效变换保持精度
应用场景
QLoRA (Quantized Low-Rank Adaptation)
结合量化与低秩适配的高效微调技术
核心技术
- • 4-bit NormalFloat (NF4) 量化
- • 低秩适配器(LoRA)微调
- • 双重量化技术优化
- • 冻结预训练权重
突破性优势
使得在单个48GB GPU上对65B参数的模型进行微调成为可能,极大降低了大型模型微调的门槛 [278]。
量化技术对比分析
| 特性 | GPTQ | AWQ | QLoRA |
|---|---|---|---|
| 核心原理 | 基于二阶信息的逐层量化 | 基于激活值分布保护显著权重 | 结合4位量化与低秩适配 |
| 量化目标 | 权重(W4A16) | 权重(W4A16) | 权重(NF4) |
| 是否需要训练 | 否(后训练量化) | 否(后训练量化) | 是(高效微调) |
| 主要优势 | 高效、通用,无需训练数据 | 精度高,实现简单,速度快 | 大幅降低微调内存需求 |
| 适用场景 | 快速部署大型模型 | 精度要求高的云端部署 | 消费级硬件微调 |
代码实战:使用bitsandbytes与Hugging Face进行模型量化
环境准备与库安装
# 安装bitsandbytes(支持CUDA 11.x和12.x)
pip install bitsandbytes
# 安装 Hugging Face Transformers
pip install transformers
# 安装 peft(用于 QLoRA)
pip install peft注意:bitsandbytes在不同CUDA版本下的安装可能需要额外配置。建议参考官方文档获取最新安装指南 [265]。
8位量化实现
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# 加载模型并启用 8 位量化
model_name = "meta-llama/Llama-2-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model_8bit = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_8bit=True,
device_map="auto"
)
# 推理示例
prompt = "The future of AI is"
inputs = tokenizer(prompt, return_tensors="pt").to(model_8bit.device)
with torch.no_grad():
outputs = model_8bit.generate(\*\*inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))配置参数
- •
load_in_8bit=True: 启用8位量化 - •
device_map="auto": 自动设备分配 - •
llm_int8_threshold: 异常值阈值
性能表现
- • 模型大小减半(约50%)
- • 精度损失通常小于1%
- • 推理速度提升20-30%
4位量化与QLoRA微调
from transformers import BitsAndBytesConfig
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
# 配置 4 位量化
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
# 加载 4 位量化模型
model_4bit = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto"
)
# 准备模型进行 QLoRA 微调
model_4bit = prepare_model_for_kbit_training(model_4bit)
# 配置 LoRA 参数
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM"
)
# 应用 QLoRA
model_lora = get_peft_model(model_4bit, lora_config)
model_lora.print_trainable_parameters()QLoRA微调优势
通过结合4位量化和LoRA技术,QLoRA使得在消费级GPU上微调大型语言模型成为可能。例如,65B参数的模型可以在单个48GB GPU上进行微调,而传统方法需要多个高端GPU。
代码实战:AWQ量化技术实现与应用
使用AutoAWQ库进行量化
# 安装AutoAWQ
pip install autoawq
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
# 定义量化配置
quant_config = {
"zero_point": True,
"q_group_size": 128,
"w_bit": 4,
"version": "GEMM"
}
# 加载模型
model = AutoAWQForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf", trust_remote_code=True)
# 准备校准数据
calib_data = [
"The future of artificial intelligence is",
"Large language models have revolutionized",
"Quantization is a technique for compressing neural networks"
]
# 执行量化
model.quantize(tokenizer, quant_config=quant_config, calib_data=calib_data)
# 保存量化模型
model.save_quantized("./llama-2-7b-awq")
tokenizer.save_pretrained("./llama-2-7b-awq")量化配置
- •
w_bit: 量化位数 - •
q_group_size: 分组大小 - •
zero_point: 零点启用
性能优势
- • 量化速度快
- • 精度保持良好
- • 硬件友好
适用场景
- • 指令微调模型
- • 多模态模型
- • 云端LLM服务
AWQ核心算法逻辑
算法步骤
- 1. 激活值分析:通过校准数据收集各层的激活值分布
- 2. 显著权重识别:基于激活值幅度识别重要权重通道
- 3. 缩放因子优化:通过网格搜索确定最优缩放参数
- 4. 量化执行:应用缩放并执行量化操作
数学原理
AWQ通过数学等效变换保护显著权重:
X' = X / S
Y = W' × X' = W × X
其中S是逐通道的缩放因子,通过放大权重同时缩小激活值,保持计算结果不变。
硬件加速与CUDA优化
WQLinear类结构
class WQLinear(torch.nn.Module):
def __init__(self, w_bit, group_size,
in_features, out_features):
super().__init__()
self.qweight = Parameter(
torch.empty(in_features,
out_features//(32//w_bit),
dtype=torch.int32))
self.scales = Parameter(
torch.empty(in_features,
out_features//group_size,
dtype=torch.float16))
self.qzeros = Parameter(
torch.empty(in_features,
out_features//group_size//(32//w_bit),
dtype=torch.int32))
def forward(self, x):
return awq_inference_engine.gemm_forward_cuda(
x, self.qweight, self.scales,
self.qzeros, self.group_size,
self.w_bit)CUDA加速优势
- • 并行反量化:在GPU上并行执行反量化操作
- • 内存优化:紧凑的int32存储格式
- • 算子融合:量化和矩阵乘法融合为单一操作
- • 带宽优化:减少内存访问次数
AWQ的CUDA实现使得4位量化模型的推理速度可以接近16位模型的水平,这在生产环境中具有重要价值。
总结与展望
技术总结
未来展望
硬件协同设计
专用AI芯片对低精度计算的原生支持将进一步释放量化潜力
混合精度策略
根据层敏感度自动选择最优量化位数的自适应方法
多模态扩展
将量化技术扩展到视觉、语音等多模态大型模型
技术挑战与机遇
主要挑战
- • 超低比特(1-2位)量化的精度保持
- • 量化模型的跨平台部署
- • 动态量化方案的实时优化
发展机遇
- • 边缘计算与移动端AI应用
- • 大规模AI服务的成本优化
- • 绿色AI与可持续发展
开启您的量化之旅
掌握LLM量化技术,释放大型语言模型的全部潜力,让AI应用更加高效、普惠