轻量化大语言模型中的Agent:从概念到边缘部署
`
轻量化大语言模型中的
`
`Agent技术
`
`
`` 从概念到边缘部署的完整指南 `
` ``智能推理`
` ``自主规划与决策能力`
` ``工具使用`
` ``扩展模型能力边界`
` ``边缘部署`
` ``资源优化与效率提升`
` ` `
``
`
`
``
``引言`
` `` 在人工智能领域,``Agent(智能体)``代表了一种从被动响应到主动执行的范式转变。与仅根据输入生成输出的传统大语言模型(LLM)不同,Agent是一个能够自主理解目标、进行决策、规划任务并采取行动以影响其环境的软件系统``[220]``。 `
` `` "Agent将LLM的语言理解能力转化为解决实际问题的行动力,是AI从'能说'到'会做'的关键一步。" `` `
` 这种``自主性(Autonomy)``是Agent最核心的特征,意味着Agent不仅仅是信息的处理者,更是任务的执行者。它能够将复杂的目标分解为一系列可执行的子任务,并根据环境反馈动态调整其策略。 `
` `` `` 为什么Agent在轻量化模型中至关重要? `
` `- `
`
- `
``
``能力增强``:通过外部工具弥补模型自身能力不足
`</li>`
`
- ` `` ``效率优化``:显著降低本地计算负载和功耗 `</li>` `
- ` `` ``隐私安全``:敏感数据保留在本地设备处理 `</li>` `
- ` `` ``离线可用``:保证核心功能在无网络环境下的可用性 `</li>` `</ul>` `</div>` `</div>` `</div>` `</section>` `` `
` ` ` `` `` `` ``Agent的核心概念与架构`
` `` `` `` `` `` `` ``Agent的关键组件`
` `` `` `` `` `` `` `` `` `` ``规划 (Planning)`
` `` 将复杂目标分解为可执行的子任务,制定最佳执行顺序和策略。Agent利用LLM的推理能力进行分析和决策``[34]``。 `
` `` `` `` `` `` `` `` ``工具使用 (Tool Use)`
` `` 调用外部函数、API或服务扩展自身能力,包括信息获取、计算执行、交互操作等多样化工具。 `
` `` `` `` `` `` `` `` ``记忆 (Memory)`
` `` 存储和管理任务过程中的所有信息,包括短期记忆、长期记忆和情景记忆,支持多步推理。 `
` `` `` `` `` `` `` `` ``行动 (Action)`
` `` 执行决策并影响环境,分为内部行动和外部行动,是Agent从"思考"走向"实践"的关键。 `
` `` `` ``Agent的推理与决策模式`
` `` `` `` `` `` `` `` `` ReAct模式:推理与行动的协同 `
` `` ReAct(Reasoning and Acting)将推理(Reasoning)和行动(Acting)紧密结合,形成"思考-行动-观察"的循环``[34]``。 `
` `` `` `` `` `` `` `` ``思考`
` ``分析任务,生成计划`
` `` `` `` `` `` ``行动`
` ``调用工具执行操作`
` `` `` `` `` `` ``观察`
` ``接收反馈,调整策略`
` `` `` `` `` `` Code Agent:以代码为行动媒介 `
` `` Code Agent将"行动"定义为生成和执行Python代码,具有更高的灵活性和表达能力``[34]``。 `
` `` `` ``主要优势:`
` `- `
`
- `• 图灵完备的编程语言表达能力` ` `
- `• 强大的自我调试和修正能力` ` `
- `• 无缝集成Python庞大生态系统` ` `
- `• 自然的中间结果存储和传递` ` `
` `` `` `` 多Agent协作:分工与协同解决问题 `
` `` 通过"管理者-执行者"架构,将复杂任务分解并分配给多个具有不同专长的Agent``[34]``。 `
` `` `` `` `` ``管理者Agent`
` ``负责任务分解、分配、流程管理和结果整合`
` `` `` ``执行者Agent`
` ``专注于特定领域的子任务执行,如搜索、检索、分析等`
` `` ` ` ``Agentic RAG:动态与智能的检索范式`
` `` `` `` ``传统RAG的局限性`
` `` `` `` `` `` 静态检索与生成的割裂 `
` `` 传统RAG系统中,检索和生成两个阶段是静态且割裂的``[219]``。系统基于用户查询进行一次性的语义相似度检索,然后直接将结果输入给LLM生成答案。 `
` `` `` ``主要问题:`
` `- `
`
- `• 检索质量直接决定生成上限` ` `
- `• 无法处理需要多步推理的复杂查询` ` `
- `• 缺乏对检索结果的批判性评估` ` `
- `• 难以处理动态变化的知识库` ` `
` `` `` 多步推理的挑战 `
` `` 传统RAG无法自动执行"检索-发现新实体-再检索"的迭代过程``[34]``。例如,回答"苹果公司现任CEO的母校是哪所?"这类多跳问答时表现不佳。 `
` `` ``多跳问答示例:`
` `` `` ``1 ``检索"苹果公司现任CEO" → "蒂姆·库克" `</div>` `` ``2 ``检索"蒂姆·库克的母校" → "奥本大学" `</div>` `</div>` `</div>` `</div>` `</div>` `</div>` `` `` `` `</div>` `</div>` `</section>` `` ``Agentic RAG解决方案`
` `` `` `` `` `` 核心思想:Agent驱动的迭代检索 `
` `` Agentic RAG将Agent的自主性、规划能力和工具使用能力注入到检索增强生成的流程中``[219]``。整个过程成为由Agent主动驱动、动态迭代和持续优化的任务。 `
` `` "RAG不再是简单的'检索-然后-生成',而是演变成一个复杂的、多步骤的推理和行动循环。" `
` `` `` `` ``Agentic RAG工作流程`
` `` `` `` `` `` `` `` ``1`` `` `` ``规划 (Planning)`
` ``分析查询意图,制定初步行动计划,确定检索策略`
` `` `` ``2`` `` `` ``检索与行动 (Retrieval & Action)`
` ``根据规划执行动态检索,调用合适的工具获取信息`
` `` `` ``3`` `` `` ``评估与反思 (Evaluation & Reflection)`
` ``批判性审视检索结果,判断相关性和完整性``[210]`` `
` `` `` ``4`` `` `` ``生成与整合 (Generation & Synthesis)`
` ``整合所有信息,生成最终全面答案`
` `` `` `` `` ``Agentic RAG的优势`
` `` `` ` ` ``资源受限环境下的部署与优化策略`
` `` `` `` `` `` ``轻量化模型技术`
` `` `` `` `` `` `` `` `` 模型压缩技术 `
` `` `` `` `` `` 高效架构设计 `
` `` `` `` `` ``DistilBERT`
` ``保留BERT 97%能力的同时,体积减小40%,速度提升60%``[424]`` `
` `` `` ``TinyBERT`
` ``通过两阶段蒸馏过程实现更高压缩比`
` `` `` ``MobileLLM`
` ``专为边缘设备优化的轻量级架构设计`
` `` `` `` ``边缘计算与移动设备部署`
` `` `` `` `` `` `` ``边缘部署的优势`
` `` `` `` `` `` `` `` ``低延迟`
` ``数据和计算在本地进行,无需网络传输,极大减少响应时间`
` `` `` `` `` `` ``高隐私`
` ``敏感数据保留在本地设备,避免传输和存储过程中的泄露风险`
` `` `` `` `` `` ``离线可用性`
` ``在网络不稳定或断开场景下依然能够正常工作`
` `` `` ``硬件加速`
` `` `` `` `` `` `` `` ``NPU`
` ``神经处理单元,专为神经网络计算设计的高能效处理器`
` `` `` `` `` `` `` ``TPU`
` ``Google的专用集成电路,为边缘设备优化的推理加速器`
` `` ``系统级优化策略`
` `` `` `` `` `` ``提示工程优化`
` `- `
`
- `
``
``精简提示设计
`</li>`
`
- ` `` ``模板化提示重用 `</li>` `
- ` `` ``动态上下文管理 `</li>` `</ul>` `</div>` `
` `` `` `` ``检索优化`
` `- `
`
- `
``
``高效索引(FAISS, ScaNN)
`</li>`
`
- ` `` ``选择性检索决策 `</li>` `
- ` `` ``分层检索策略 `</li>` `</ul>` `</div>` `
` `` `` `` ``联邦学习`
` `- `
`
- `
``
``个性化Agent训练
`</li>`
`
- ` `` ``模型持续改进 `</li>` `
- ` `` ``隐私保护机制 `</li>` `</ul>` `</div>` `</div>` `</div>` `</div>` `</div>` `</section>` `` `
` ` ` `` `` `` ``代码实战:构建轻量级Agentic RAG系统`
` `` `` `` `` `` `` ``环境准备与依赖安装`
` `` `` `
` ``pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu pip install transformers accelerate sentence-transformers faiss-cpu pip install langchain langchain-community`` `` `` `` ``核心依赖`
` `- `
`
- `• torch: PyTorch深度学习框架` ` `
- `• transformers: Hugging Face模型库` ` `
- `• sentence-transformers: 句子嵌入模型` ` `
- `• faiss-cpu: 高效向量搜索` ` `
` `` ``Agent框架`
` `- `
`
- `• langchain: Agent构建框架` ` `
- `• accelerate: 模型加速库` ` `
- `• 其他工具库` ` `
` `` `` ``构建Agent核心组件`
` `` `` `` `` `` `` `` `` `` `` 检索器 (Retriever) 实现 `
` `` `` `
` ``class SimpleRetriever: def __init__(self, documents: List[str], embedding_model_name: str = 'all-MiniLM-L6-v2'): """初始化一个简单的检索器""" self.documents = documents self.embedding_model = SentenceTransformer(embedding_model_name) self.index = self._build_index() def _build_index(self) -> faiss.IndexFlatIP: """构建FAISS索引""" doc_embeddings = self.embedding_model.encode(self.documents, convert_to_numpy=True) doc_embeddings = doc_embeddings / np.linalg.norm(doc_embeddings, axis=1, keepdims=True) index = faiss.IndexFlatIP(doc_embeddings.shape[1]) index.add(doc_embeddings.astype('float32')) return index def retrieve(self, query: str, top_k: int = 3) -> List[str]: """根据查询检索最相关的文档""" query_embedding = self.embedding_model.encode([query], convert_to_numpy=True) query_embedding = query_embedding / np.linalg.norm(query_embedding, axis=1, keepdims=True) scores, indices = self.index.search(query_embedding.astype('float32'), top_k) return [self.documents[i] for i in indices[0]]`` `` `` `` `` `` `` 生成器 (Generator) 实现 `
` `` `` `
` ``class SimpleGenerator: def __init__(self, model_name: str = "microsoft/DialoGPT-medium"): """初始化一个简单的生成器""" self.tokenizer = AutoTokenizer.from_pretrained(model_name) if self.tokenizer.pad_token is None: self.tokenizer.pad_token = self.tokenizer.eos_token # 加载模型并应用动态量化 self.model = AutoModelForCausalLM.from_pretrained(model_name) self.model = quant.quantize_dynamic( self.model, {torch.nn.Linear}, dtype=torch.qint8 ) self.pipeline = pipeline("text-generation", model=self.model, tokenizer=self.tokenizer) def generate(self, prompt: str, max_new_tokens: int = 100) -> str: """根据提示生成文本""" response = self.pipeline(prompt, max_new_tokens=max_new_tokens, num_return_sequences=1, pad_token_id=self.tokenizer.eos_token_id)[0]['generated_text'] return response[len(prompt):].strip()`` `` `` `` `` `` Agent核心逻辑 `
` `` `` `
` ``class SimpleAgent: def __init__(self, retriever: SimpleRetriever, generator: SimpleGenerator): """初始化一个简单的ReAct Agent""" self.retriever = retriever self.generator = generator def run(self, question: str) -> str: """运行Agent以回答一个问题""" # Step 1: 规划 - 决定是否需要检索 retrieved_docs = self.retriever.retrieve(question) # Step 2: 构建包含检索结果的Prompt context ="\n".join(retrieved_docs) prompt = f"""Answer the following question based on the provided context. If the answer is not in the context, say "I don't know." Context: {context} Question: {question} Answer:""" # Step 3: 生成答案 answer = self.generator.generate(prompt) return answer`` `` `` ``模型优化与量化`
` `` `` `` `` `` `` `` `` PyTorch动态量化 `
` `` `` `
` ``import torch.quantization as quant # 在模型加载后应用 self.model = quant.quantize_dynamic( self.model, {torch.nn.Linear}, dtype=torch.qint8 ) print("Model quantized with dynamic quantization.")``动态量化主要针对模型权重进行量化,激活值在推理时动态量化,适合计算瓶颈在权重读取的模型。`
` `` `` `` `` ONNX格式转换 `
` `` `` `
` ``import torch.onnx torch.onnx.export( model, (dummy_input['input_ids'], dummy_input['attention_mask']), "dialogpt_model.onnx", export_params=True, opset_version=11, do_constant_folding=True, input_names=['input_ids', 'attention_mask'], output_names=['output'] )``ONNX 格式提供跨框架互操作性,可使用 ONNX Runtime 进行高效推理``[167]`` ``[185]``。 `
` `` `` ``部署到边缘设备`
` `` `` `` `` `` `` `` `` `` ``Streamlit Web应用`
` ``使用Streamlit快速构建交互式Web界面,便于测试和演示。`
` `` streamlit run app.py `` `` `` `` `` `` `` ``Docker容器`
` ``打包为Docker容器,确保环境一致性和便捷部署。`
` `` docker build -t agent . `` `` `` `` `` `` ``边缘设备部署`
` ``在Jetson Nano等边缘设备上运行,利用硬件加速。`
` `` ./agent --device cuda `` `` ` ` ``高级主题与未来展望`
` `` `` `` `` `` ``多Agent系统在边缘的应用`
` `` `` `` `` `` `` 协作式任务处理 `
` ` `
`
`
`` 在智能家居等环境中,中央协调Agent接收复杂指令,分发给多个执行Agent(灯光、窗帘、音响等)协同完成任务。 `
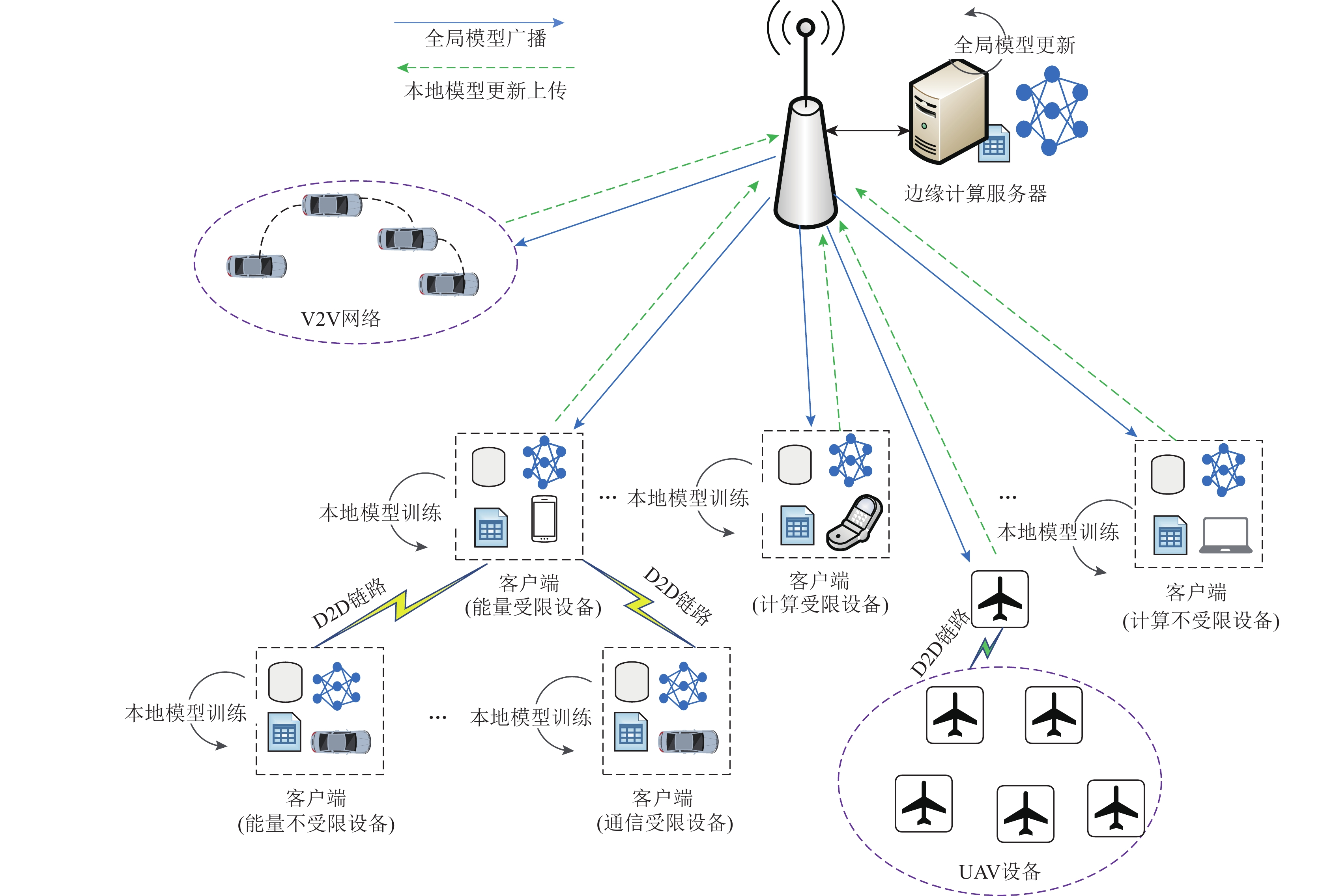
` `` `` `` `` 分布式学习与推理 `
` ` `
`
`
`` 通过联邦学习机制,多个边缘设备在不共享原始数据的情况下协同训练全局模型,保护隐私的同时提升模型性能。 `
` `` ``挑战与机遇`
` `` `` `` `` `` `` `` 主要挑战 `
` `` `` `` `` `` `` `` ``持续学习`
` ``如何在资源受限设备上实现高效的在线学习和模型更新`
` `` `` `` `` `` ``安全隐私`
` ``边缘设备本身可能成为攻击目标,需要强大的安全机制`
` `` `` `` `` `` ``标准化`
` ``缺乏统一标准和开放生态系统,影响技术普及`
` `` `` `` 发展机遇 `
` `` `` `` ``技术创新`
` `- `
`
- `
``
``更轻量、高效的边缘学习算法
`</li>`
`
- ` `` ``自适应模型压缩技术 `</li>` `
- ` `` ``多模态Agent系统 `</li>` `</ul>` `</div>` `
` ``应用场景`
` `- `
`
- `
``
``智能物联网设备
`</li>`
`
- ` `` ``自动驾驶系统 `</li>` `
- ` `` ``个性化AI助手 `</li>` `</ul>` `</div>` `</div>` `</div>` `</div>` `</div>` `</div>` `` `
` `` `</div>` `</div>` `</section>` `` ``未来愿景`
` `` `` `` "轻量化Agent技术将推动AI从云端向边缘的全面迁移,实现真正的普惠智能。未来的智能设备将不仅仅是执行命令的工具,而是能够理解意图、主动规划、协同合作的智能伙伴。" `
` `` `` ` `
`
`
`` ` ` `` `` `</main>` `` </body> </html>` `` ``参考文献`
` `` `` `` `` `` ``[34]`` `` Multi-Agentic RAG with Hugging Face Code Agents `` `` `` ``[95]`` `` Step-by-Step Guide to Agentic RAG for Large-Scale Use `` `` `` `` ``[170]`` `` Deploying PyTorch Models on ARM Edge Devices `` `` `` `` ``[185]`` `` Beyond the Basics: How to Succeed with PyTorch Quantization `` `` `` `` `` `` ``[189]`` `` Reduce Memory Footprint of Sentence Transformer Models `` `` `` ``[191]`` `` How to Deploy a Trainable Model on iPhone `` `` `` ``[192]`` `` PyTorch Mobile Tutorial `` `` `` ``[193]`` `` PyTorch Mobile Vision Transformer Tutorial `` `` `` ``[210]`` `` LangGraph Self-Correcting Agent Code Generation `` `` `` `` ``[219]`` `` The Rise of Agentic RAG Systems `` `` `` ``[220]`` `` Beginner's Guide to Agentic AI RAG - Easy and Fast `` `` `` ``[223]`` `` Agentic RAG Research Paper `` `` ` - ` `` ``自动驾驶系统 `</li>` `
- ` `` ``自适应模型压缩技术 `</li>` `
- ` `` ``模型持续改进 `</li>` `
- ` `` ``选择性检索决策 `</li>` `
- ` `` ``模板化提示重用 `</li>` `
- ` `` ``效率优化``:显著降低本地计算负载和功耗 `</li>` `